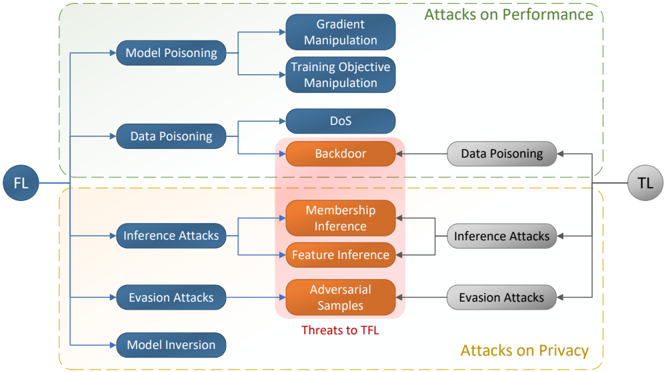
## Diagram: Taxonomy of Attacks on Federated Learning (FL)
### Overview
This image is a technical diagram illustrating a taxonomy of security and privacy attacks within the context of Federated Learning (FL). It categorizes attacks based on their primary impact—either on system performance or on data privacy—and maps the relationships between attack types, their specific techniques, and the entities involved (FL and TL).
### Components/Axes
The diagram is structured as a flowchart with the following key components:
1. **Primary Entities:**
* **FL (Federated Learning):** Positioned on the far left in a dark blue circle. It is the source or target of various attacks.
* **TL (Trusted Learning / Threat Actor?):** Positioned on the far right in a grey circle. It is connected to specific attack vectors, suggesting it may be an external threat actor or a trusted entity being attacked.
2. **Major Categories (Grouped by Dashed Borders):**
* **Attacks on Performance:** Enclosed in a light green dashed rectangle at the top.
* **Attacks on Privacy:** Enclosed in a light yellow dashed rectangle at the bottom.
3. **Attack Vectors (Blue Nodes):** These are the primary methods originating from or targeting FL.
* Model Poisoning
* Data Poisoning
* Inference Attacks
* Evasion Attacks
* Model Inversion
4. **Specific Techniques/Threats (Orange Nodes):** These are concrete attack methods, highlighted with an orange background and grouped within a central red-shaded area labeled **"Threats to TFL"**.
* Backdoor
* Membership Inference
* Feature Inference
* Adversarial Samples
5. **Sub-Techniques (Dark Blue Nodes):** These are specific implementations of the broader attack vectors.
* Under **Model Poisoning**: Gradient Manipulation, Training Objective Manipulation.
* Under **Data Poisoning**: DoS (Denial of Service).
* (Note: "Data Poisoning" also appears as a grey node on the right, connected to TL).
6. **Flow and Relationships (Arrows):**
* Arrows originate from **FL** and point to the primary attack vectors (Model Poisoning, Data Poisoning, etc.).
* Arrows from the primary attack vectors point to their specific techniques (e.g., Model Poisoning -> Gradient Manipulation).
* Arrows from **TL** point to grey nodes labeled "Data Poisoning," "Inference Attacks," and "Evasion Attacks," which then connect to the central orange "Threats to TFL" nodes. This indicates these threats can also be launched from or against the TL entity.
* The central orange nodes (Backdoor, Membership Inference, etc.) are the convergence points for multiple attack paths.
### Detailed Analysis
The diagram creates a clear hierarchy and relationship map:
* **Performance Attacks** focus on degrading the model's functionality.
* **Model Poisoning** aims to corrupt the learning process via **Gradient Manipulation** or **Training Objective Manipulation**.
* **Data Poisoning** aims to corrupt the training data, leading to **DoS** or enabling a **Backdoor** attack.
* **Privacy Attacks** aim to extract sensitive information from the model or training data.
* **Inference Attacks** can determine **Membership Inference** (whether a data point was in the training set) or **Feature Inference** (reconstructing input features).
* **Evasion Attacks** use **Adversarial Samples** to fool the model during inference.
* **Model Inversion** is listed as a standalone privacy attack vector.
* **Central "Threats to TFL":** The four orange nodes (Backdoor, Membership Inference, Feature Inference, Adversarial Samples) are explicitly highlighted as core threats. They are the specific, actionable techniques that result from the broader attack vectors. The diagram shows they can be reached via multiple paths (e.g., a Backdoor can be created through Data Poisoning from FL or from TL).
### Key Observations
1. **Dual-Origin Threats:** The diagram explicitly shows that critical threats like Backdoor, Inference, and Evasion attacks can originate from both the FL system itself and the external TL entity.
2. **Convergence on Core Threats:** Multiple attack vectors (Data Poisoning, Inference Attacks, Evasion Attacks) funnel into the same set of concrete threats (the orange nodes), indicating these are the most critical outcomes to defend against.
3. **Taxonomy by Impact:** The primary organizational principle is the attack's goal (Performance vs. Privacy), not the attacker's method, which is useful for defense prioritization.
4. **Model Poisoning Specificity:** Model Poisoning is uniquely broken down into two technical sub-methods (Gradient and Objective Manipulation), suggesting it is a well-studied or particularly nuanced attack surface.
### Interpretation
This diagram serves as a conceptual map for understanding the threat landscape in Federated Learning systems. It moves beyond a simple list of attacks to show their interconnections and ultimate objectives.
* **What it demonstrates:** It argues that FL security is not a single problem but a matrix of concerns. Defenders must protect against both **corruption of the learning process** (performance attacks) and **leakage of confidential data** (privacy attacks). The central orange zone represents the most tangible risks—backdoored models, privacy breaches, and manipulated outputs—that these abstract attack vectors aim to achieve.
* **Relationships:** The flow from FL/TL to broad categories to specific techniques illustrates a cause-and-effect chain. The bidirectional potential (attacks from FL or TL) highlights the complex trust assumptions in FL, where participants can be both victims and perpetrators.
* **Notable Insight:** The inclusion of "Model Inversion" as a separate vector from "Inference Attacks" suggests a distinction in the taxonomy between attacks that infer properties about the data (inference) and those that reconstruct the data itself (inversion). The diagram's structure implies that while all are threats, Backdoor, Inference, and Evasion attacks are of primary, immediate concern to TFL (likely "Trusted Federated Learning" or "The Federated Learning" system).
**Language Note:** All text in the image is in English.