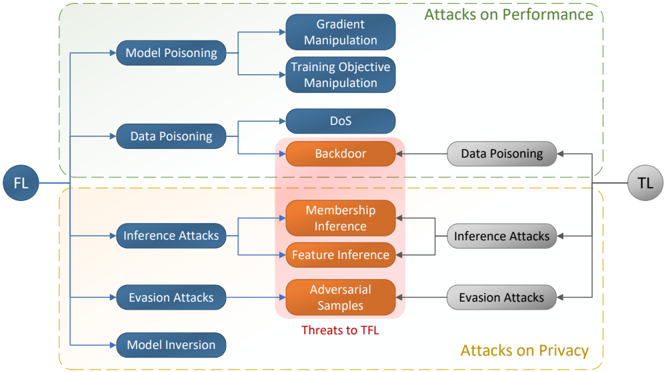
## Diagram: Threat Landscape of Federated Learning (FL) and Transfer Learning (TL)
### Overview
The diagram illustrates a conceptual threat landscape for machine learning systems, focusing on Federated Learning (FL) and Transfer Learning (TL). It categorizes attacks into two primary domains: **Attacks on Performance** (green) and **Attacks on Privacy** (orange), with a central "Threats to TFL" section (pink) linking vulnerabilities across both domains. Arrows indicate directional relationships between attack types and their impacts.
---
### Components/Axes
1. **Main Sections**:
- **Attacks on Performance** (top, green):
- **Model Poisoning**: Gradient Manipulation, Training Objective Manipulation.
- **Data Poisoning**: Denial of Service (DoS).
- **Attacks on Privacy** (bottom, orange):
- **Inference Attacks**: Membership Inference, Feature Inference.
- **Evasion Attacks**: Adversarial Samples.
- **Model Inversion**: Direct attack on model parameters.
- **Threats to TFL** (center, pink):
- **Data Poisoning**, **Inference Attacks**, **Evasion Attacks** (shared vulnerabilities between FL and TL).
2. **Flow Arrows**:
- Connect FL-specific attacks to TL-specific threats (e.g., FL Data Poisoning → TL Data Poisoning).
- Highlight bidirectional risks (e.g., Adversarial Samples in Privacy Attacks affect both FL and TL).
3. **Color Coding**:
- **Green**: Performance-focused attacks (FL).
- **Orange**: Privacy-focused attacks (TL).
- **Pink**: Shared threats to Transfer Learning (TFL).
---
### Detailed Analysis
- **Attacks on Performance (FL)**:
- **Model Poisoning**: Targets model training via Gradient Manipulation (altering gradients during training) or Training Objective Manipulation (modifying loss functions).
- **Data Poisoning**: Involves injecting malicious data to trigger Denial of Service (DoS) attacks, degrading model performance.
- **Attacks on Privacy (TL)**:
- **Inference Attacks**: Exploit model outputs to infer sensitive data (Membership Inference: determining if data was in training; Feature Inference: extracting specific features).
- **Evasion Attacks**: Use Adversarial Samples (perturbed inputs) to bypass model defenses.
- **Model Inversion**: Directly reconstructs training data from model parameters.
- **Threats to TFL**:
- **Data Poisoning**: FL vulnerabilities propagate to TL, compromising downstream models.
- **Inference Attacks**: Privacy risks in FL affect TL models built on FL outputs.
- **Evasion Attacks**: Adversarial samples in FL can evade TL models, creating cross-domain risks.
---
### Key Observations
1. **Color-Coded Threats**: Performance attacks (green) and privacy attacks (orange) are visually distinct, but their impacts converge in the pink "Threats to TFL" section.
2. **Bidirectional Risks**: Arrows show that FL attacks (e.g., Data Poisoning) directly threaten TL, while TL-specific attacks (e.g., Membership Inference) may originate from FL vulnerabilities.
3. **Central Vulnerability**: The "Threats to TFL" section acts as a bridge, emphasizing that FL security is critical to protecting TL systems.
---
### Interpretation
The diagram underscores the interconnectedness of FL and TL security. While FL focuses on collaborative training (green), its vulnerabilities (e.g., Model Poisoning) can cascade into TL systems (orange), creating shared risks like Data Poisoning and Inference Attacks. The pink "Threats to TFL" section highlights that securing FL is not just about preserving local model performance but also about preventing cross-domain attacks that compromise downstream applications. For example:
- A Model Inversion attack in FL could expose sensitive training data, enabling Adversarial Samples in TL.
- DoS attacks in FL might degrade the quality of FL outputs, indirectly weakening TL models.
This suggests that FL and TL security strategies must be co-designed, as threats in one domain often propagate to the other. The diagram also implies that privacy-preserving techniques (e.g., differential privacy) in FL could mitigate risks in TL, reducing the attack surface for both performance and privacy.