\n
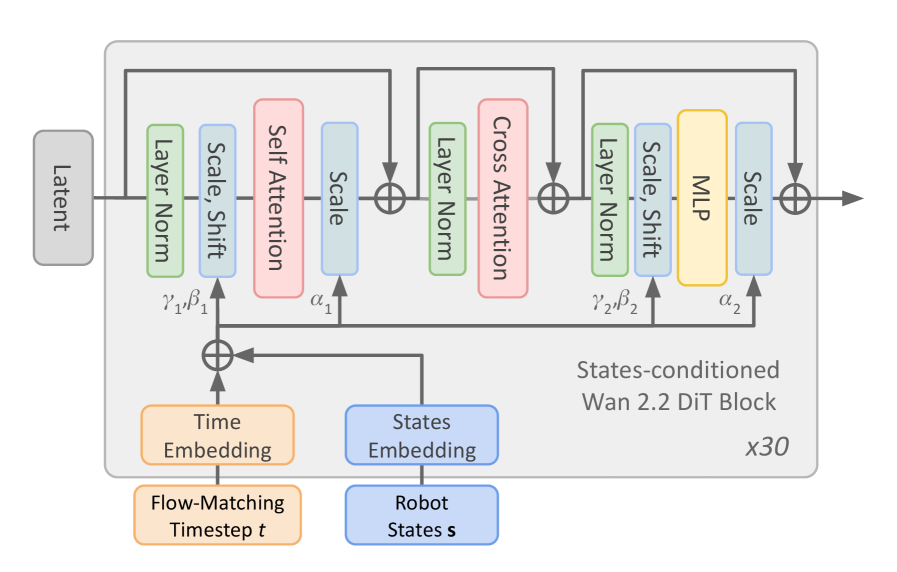
## Diagram: States-conditioned Wan 2.2 DiT Block Architecture
### Overview
The image depicts a diagram of a "States-conditioned Wan 2.2 DiT Block" repeated 30 times (indicated by "x30" in the bottom-right). It illustrates the flow of data through a series of processing layers within this block, starting with a "Latent" input and a "Flow-Matching Timestep t" input, and culminating in an output. The diagram highlights the use of attention mechanisms and normalization layers.
### Components/Axes
The diagram consists of the following components:
* **Latent:** Input node, positioned on the left.
* **Flow-Matching Timestep t:** Input node, positioned at the bottom-left.
* **Robot States s:** Input node, positioned at the bottom-center.
* **Time Embedding:** Processing block, positioned below "Flow-Matching Timestep t".
* **States Embedding:** Processing block, positioned below "Robot States s".
* **Layer Norm:** Normalization layer, appearing multiple times.
* **Scale, Shift:** Processing block, appearing multiple times.
* **Self Attention:** Attention mechanism, appearing once.
* **Cross Attention:** Attention mechanism, appearing once.
* **MLP:** Multi-Layer Perceptron, appearing once.
* **Scale:** Processing block, appearing multiple times.
* **Addition Symbols (⊕):** Representing the addition of data streams.
* **Wan 2.2 DiT Block:** Overall block title, positioned in the center-right.
* **γ₁, β₁:** Parameters associated with the first "Scale, Shift" block.
* **α₁:** Parameter associated with the "Scale" block after "Self Attention".
* **γ₂, β₂:** Parameters associated with the second "Scale, Shift" block.
* **α₂:** Parameter associated with the "Scale" block after "Cross Attention".
There are no explicit axes in this diagram; it represents a data flow rather than a plotted graph.
### Detailed Analysis or Content Details
The data flow proceeds as follows:
1. "Latent" input enters a "Layer Norm" block.
2. The output of "Layer Norm" goes to a "Scale, Shift" block (with parameters γ₁, β₁).
3. The output of "Scale, Shift" is fed into a "Self Attention" block.
4. The output of "Self Attention" is scaled by α₁ and then added (⊕) to the output of the "Scale, Shift" block.
5. The result is passed through another "Layer Norm" block.
6. The output of the second "Layer Norm" goes to a "Cross Attention" block.
7. "Flow-Matching Timestep t" is processed by "Time Embedding".
8. "Robot States s" is processed by "States Embedding".
9. The outputs of "Time Embedding" and "States Embedding" are added (⊕) and fed into the "Cross Attention" block.
10. The output of "Cross Attention" is scaled by α₂ and then added (⊕) to the output of the second "Layer Norm" block.
11. The result is passed through another "Layer Norm" block.
12. The output of the third "Layer Norm" goes to a "Scale, Shift" block (with parameters γ₂, β₂).
13. The output of the "Scale, Shift" block is fed into an "MLP".
14. The output of the "MLP" is scaled and then added (⊕) to the output of the "Scale, Shift" block, producing the final output.
The entire sequence of blocks is repeated 30 times, as indicated by "x30".
### Key Observations
The diagram emphasizes the use of attention mechanisms ("Self Attention" and "Cross Attention") within the block. The repeated addition operations (⊕) suggest a residual connection architecture, common in deep learning models. The presence of "Scale, Shift" blocks and "Layer Norm" indicates normalization and transformation of the data. The inputs "Flow-Matching Timestep t" and "Robot States s" suggest the model is conditioned on both time and robot state information.
### Interpretation
This diagram represents a building block within a larger neural network architecture, likely designed for sequence modeling or reinforcement learning. The "States-conditioned Wan 2.2 DiT Block" appears to be a sophisticated module that integrates information from multiple sources (latent representation, time, and robot state) using attention mechanisms and normalization techniques. The repeated application of this block (x30) suggests a deep network with a significant capacity for learning complex relationships. The "Flow-Matching" terminology hints at a connection to generative modeling or trajectory optimization. The architecture is designed to process sequential data, potentially for tasks like robot control or time-series prediction. The parameters γ₁, β₁, α₁, γ₂, β₂, and α₂ represent learnable weights that allow the model to adapt to the specific characteristics of the data. The diagram provides a high-level overview of the block's structure and data flow, but does not reveal details about the specific implementation of the attention mechanisms or the MLP.