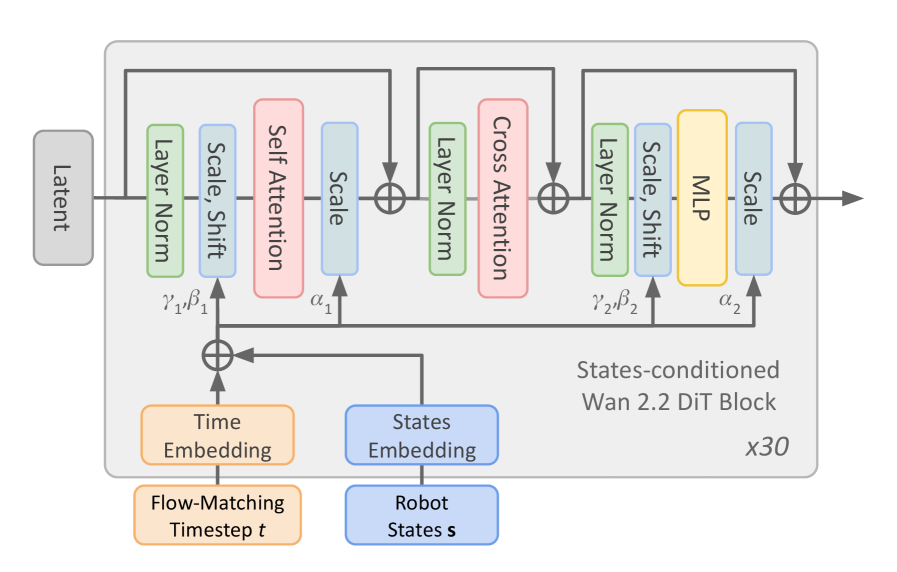
\n
## Neural Network Architecture Diagram: States-conditioned Wan 2.2 DiT Block
### Overview
The image is a technical block diagram illustrating the architecture of a single "States-conditioned Wan 2.2 DiT Block," which is repeated 30 times (`x30`). This block processes a `Latent` input, conditioned on a `Time Embedding` (derived from a `Flow-Matching Timestep t`) and a `States Embedding` (derived from `Robot States s`). The diagram details the internal layers, data flow, and parameter injection points within this transformer-based block.
### Components/Axes
The diagram is structured as a flowchart with labeled rectangular blocks, circular addition nodes, and directional arrows. The primary components are:
1. **Inputs (Left & Bottom):**
* `Latent`: The main input tensor, entering from the left.
* `Time Embedding` (Orange box): Derived from `Flow-Matching Timestep t` (Orange box below it).
* `States Embedding` (Blue box): Derived from `Robot States s` (Blue box below it).
2. **Main Processing Block (Central Gray Box):** Contains three sequential sub-blocks, each with a residual connection.
* **Sub-block 1:** `Layer Norm` (Green) -> `Scale, Shift` (Blue) -> `Self Attention` (Pink) -> `Scale` (Blue). Parameters `γ₁, β₁` and `α₁` are injected here.
* **Sub-block 2:** `Layer Norm` (Green) -> `Cross Attention` (Pink).
* **Sub-block 3:** `Layer Norm` (Green) -> `Scale, Shift` (Blue) -> `MLP` (Yellow) -> `Scale` (Blue). Parameters `γ₂, β₂` and `α₂` are injected here.
3. **Conditioning Injection Points:**
* The combined `Time Embedding` and `States Embedding` (via a circular addition node) feed into the `Scale, Shift` layers of Sub-block 1 and Sub-block 3, providing parameters `γ₁, β₁` and `γ₂, β₂` respectively.
* The combined embedding also feeds directly into the `Scale` layers following the `Self Attention` and `MLP` modules, providing parameters `α₁` and `α₂`.
4. **Output (Right):** The processed tensor exits to the right after the final residual addition.
5. **Metadata:**
* Title/Label: `States-conditioned Wan 2.2 DiT Block` (Bottom right of the main gray box).
* Repetition Factor: `x30` (Bottom right corner).
### Detailed Analysis
**Data Flow & Layer Sequence:**
1. The `Latent` input first passes through a `Layer Norm`.
2. It then enters a `Scale, Shift` layer, which is modulated by parameters (`γ₁, β₁`) derived from the combined Time and States embeddings.
3. The normalized and scaled features undergo `Self Attention`.
4. The output of the attention is scaled by a factor `α₁` (also from the combined embeddings).
5. A residual connection adds the original `Latent` input to this processed output.
6. This sum goes through another `Layer Norm` and then `Cross Attention`. The diagram does not explicitly show the source for the cross-attention, but it is typically a secondary input like text or, in this context, possibly the robot state information.
7. Another residual connection adds the input from step 5 to the cross-attention output.
8. This sum goes through a third `Layer Norm`, followed by another `Scale, Shift` layer modulated by (`γ₂, β₂`).
9. The features are processed by an `MLP` (Multi-Layer Perceptron).
10. The MLP output is scaled by `α₂`.
11. A final residual connection adds the input from step 7 to this scaled output, producing the final block output.
**Parameter Notation:**
* `γ₁, β₁`, `γ₂, β₂`: Scale and shift parameters for feature modulation, likely applied in an affine transformation (e.g., `γ * x + β`).
* `α₁`, `α₂`: Scalar scaling parameters applied after attention and MLP operations.
### Key Observations
1. **Conditioning Mechanism:** The architecture uses a sophisticated conditioning scheme where robot states and diffusion timestep are embedded and then used to generate multiple sets of parameters (`γ, β, α`) that modulate the main latent features at different stages (before attention/MLP and after).
2. **Hybrid Attention:** The block contains both `Self Attention` (for intra-latent reasoning) and `Cross Attention` (for integrating external information, presumably the robot states).
3. **Residual Design:** The diagram shows three distinct residual addition points (marked with `⊕`), creating a deep, gradient-friendly pathway.
4. **Modular Repetition:** The label `x30` indicates this entire complex block is stacked 30 times, forming a deep network.
5. **Color Coding:** The diagram uses color to group similar operations: Green for Normalization, Blue for Scaling/Shifting, Pink for Attention, Yellow for MLP, Orange for Time-related components, and Blue for State-related components.
### Interpretation
This diagram details a specialized **Diffusion Transformer (DiT)** block designed for **robotic control tasks**. The "Wan 2.2" designation likely refers to a specific model version or architecture variant.
* **Purpose:** The block's function is to iteratively denoise or refine a `Latent` representation (which could encode a robot's trajectory, image, or plan) over 30 layers. The process is guided by two critical pieces of information: the diffusion timestep (`t`), which controls the noise level, and the current robot states (`s`), which provide real-world context.
* **How Elements Relate:** The `Time Embedding` and `States Embedding` are not merely concatenated to the input. Instead, they are fused and then used to generate *dynamic parameters* that actively transform the features within the main network. This is a form of **adaptive normalization** or **hypernetwork-based conditioning**, allowing the model to drastically change its behavior based on the robot's current situation and the diffusion process stage.
* **Significance:** This architecture is designed for high-precision, state-aware generation. The cross-attention layer is crucial for grounding the generated output in the actual physical state of the robot. The deep stack (30 blocks) suggests a high-capacity model capable of learning complex, multi-step planning or control policies. The use of "Flow-Matching" indicates it may be based on a modern, continuous-time formulation of diffusion models, which can be more efficient than discrete noising schedules.