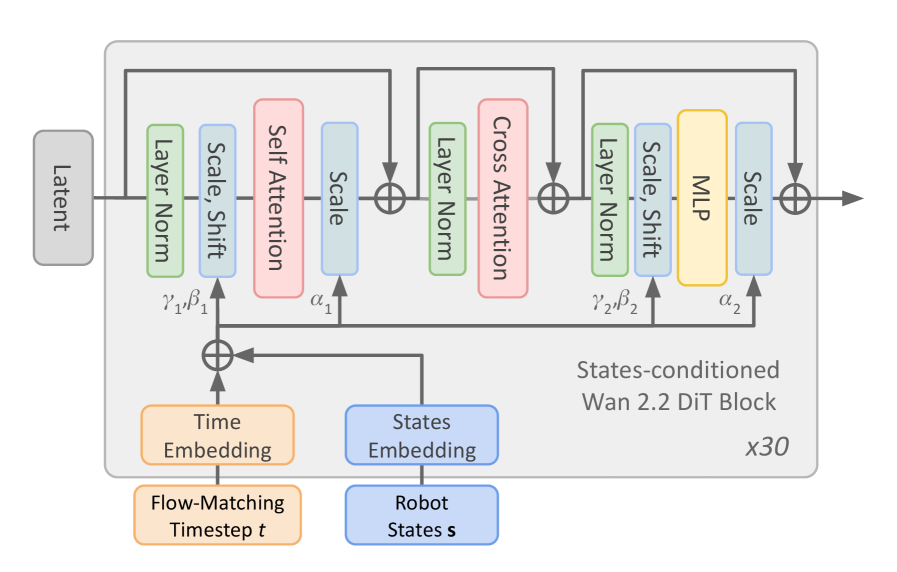
## Diagram: States-Conditioned W2.2 DiT Block Architecture
### Overview
The diagram illustrates a neural network architecture labeled as a "States-conditioned W2.2 DiT Block," repeated 30 times (x30). It integrates latent inputs, time embeddings, and robot state embeddings through a series of attention mechanisms, normalization layers, and multi-layer perceptrons (MLPs). The flow is structured with explicit parameterization (γ, β, α) and conditional processing.
---
### Components/Axes
1. **Inputs**:
- **Latent**: Gray rectangle on the left, serving as the primary input.
- **Time Embedding**: Orange rectangle labeled "Flow-Matching Timestep t."
- **States Embedding**: Blue rectangle labeled "Robot States s."
2. **Processing Layers**:
- **Layer Norm**: Green rectangles (two instances).
- **Scale/Shift**: Light blue rectangles (four instances, labeled with α₁, α₂, γ₁, β₁, γ₂, β₂).
- **Self Attention**: Pink rectangle.
- **Cross Attention**: Pink rectangle.
- **MLP**: Yellow rectangle.
3. **Output**:
- Final output arrow labeled "States-conditioned W2.2 DiT Block x30."
4. **Legend**:
- Colors map components to their types (e.g., pink = attention, yellow = MLP).
---
### Detailed Analysis
1. **Flow Path**:
- **Latent** → **Layer Norm** (γ₁, β₁) → **Scale** (α₁) → **Self Attention** → **Scale** (α₁) → **Layer Norm** (γ₂, β₂) → **Cross Attention** → **Layer Norm** (γ₂, β₂) → **Scale** (α₂) → **MLP** → **Scale** (α₂) → Output.
- **Time Embedding** and **States Embedding** feed into the block, likely conditioning the attention and MLP layers.
2. **Parameterization**:
- Scaling factors (α₁, α₂) and normalization parameters (γ₁, β₁, γ₂, β₂) are explicitly defined, suggesting trainable or fixed hyperparameters.
3. **Repetition**:
- The block is repeated 30 times (x30), indicating a transformer-like architecture with stacked layers.
---
### Key Observations
1. **Modular Design**:
- The block combines attention mechanisms (self and cross) with MLP layers, typical of diffusion models or transformers.
- Normalization (Layer Norm) and scaling (Scale/Shift) are interspersed to stabilize gradients.
2. **Conditioning**:
- **Time Embedding** and **States Embedding** are integrated to condition the model on temporal and robotic state information, critical for tasks like motion planning or control.
3. **Repetition**:
- The x30 repetition suggests depth, enabling hierarchical feature extraction.
---
### Interpretation
This architecture is likely part of a diffusion model or transformer-based system for robotics or time-series prediction. The **self-attention** and **cross-attention** layers enable the model to capture temporal dependencies and integrate external state information. The **MLP** processes high-level features, while **Layer Norm** and **Scale/Shift** ensure stable training. The explicit parameterization (γ, β, α) allows fine-grained control over layer behavior. The repetition (x30) implies a deep network capable of modeling complex dynamics, with conditioning on time and robot states enabling adaptability to specific tasks.