\n
## Diagram: Distributed Training with Feedforward Neural Networks
### Overview
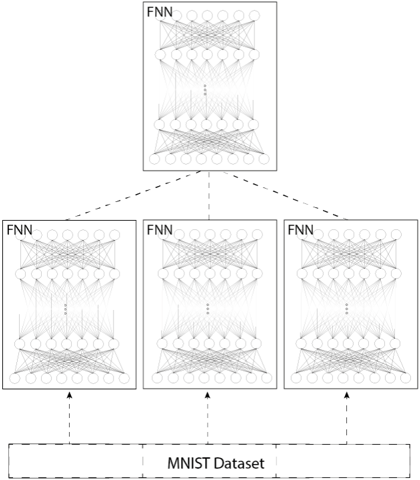
The image depicts a diagram illustrating a distributed training setup for Feedforward Neural Networks (FNNs) using the MNIST dataset. The diagram shows a single dataset being fed into three separate FNNs, with the output of these FNNs converging into a single, higher-level FNN. The connections between the components are indicated by dashed lines.
### Components/Axes
The diagram consists of the following components:
* **MNIST Dataset:** Located at the bottom center, labeled "MNIST Dataset".
* **FNNs (x3):** Three identical Feedforward Neural Networks positioned in a row at the bottom. Each is labeled "FNN".
* **Higher-Level FNN:** A single Feedforward Neural Network positioned at the top center, labeled "FNN".
* **Connections:** Dashed lines connecting the MNIST Dataset to each of the three FNNs, and dashed lines connecting each of the three FNNs to the higher-level FNN.
There are no axes or scales present in this diagram.
### Detailed Analysis or Content Details
The diagram shows a parallel processing architecture. The MNIST dataset is the input source. This dataset is distributed to three identical FNNs. Each of these FNNs processes the data independently. The outputs of these three FNNs are then combined and fed into a single, higher-level FNN.
Each FNN appears to have approximately 4 layers, with the number of nodes decreasing in each successive layer. The exact number of nodes per layer is difficult to determine due to the density of the connections. The connections within each FNN are fully connected, as indicated by the numerous lines between nodes in adjacent layers.
The dashed lines indicate the flow of data. The dashed lines from the MNIST dataset to the FNNs suggest a data distribution process. The dashed lines from the FNNs to the higher-level FNN suggest a data aggregation or fusion process.
### Key Observations
* The diagram illustrates a distributed training approach, where the workload is divided among multiple FNNs.
* The use of identical FNNs suggests that each FNN is learning the same task, and their outputs are being combined to improve the overall performance.
* The higher-level FNN likely performs a meta-learning task, such as combining the outputs of the individual FNNs to make a final prediction.
* The diagram does not provide any information about the training process, such as the learning rate, the optimization algorithm, or the loss function.
### Interpretation
This diagram represents a distributed learning architecture, likely used to improve the robustness and scalability of a machine learning model. By distributing the training workload across multiple FNNs, the system can potentially reduce the training time and improve the generalization performance. The higher-level FNN acts as an aggregator, combining the knowledge learned by the individual FNNs. This architecture could be used for tasks such as image classification, object detection, or natural language processing. The use of the MNIST dataset suggests that the model is being trained to recognize handwritten digits. The diagram is a conceptual representation and does not provide any specific details about the implementation or performance of the system. It is a high-level overview of the architecture, intended to convey the general idea of distributed training.