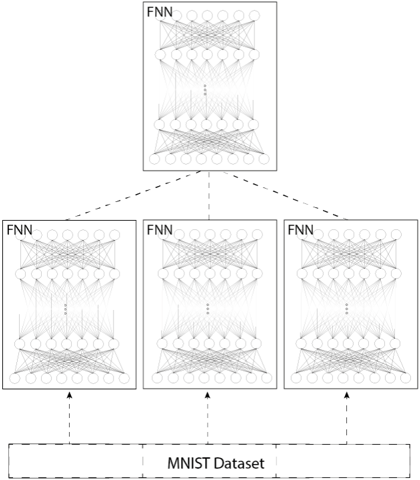
## Diagram: Ensemble of Feedforward Neural Networks (FNNs) for MNIST
### Overview
The image is a technical diagram illustrating a hierarchical or ensemble architecture of Feedforward Neural Networks (FNNs). It depicts a single top-level FNN connected to three subordinate FNNs, all of which are trained on or receive input from the MNIST dataset. The diagram uses a schematic representation of neural network layers (nodes and connections) within each FNN block.
### Components/Axes
The diagram is composed of the following labeled components, arranged in a top-down hierarchical flow:
1. **Top Component:** A single rectangular box labeled **"FNN"** in its top-left corner. Inside, it contains a schematic drawing of a multi-layer neural network with an input layer (top row of circles), multiple hidden layers (middle rows of circles), and an output layer (bottom row of circles). All nodes are densely interconnected with lines representing weights.
2. **Middle Components:** Three identical rectangular boxes, each also labeled **"FNN"** in their top-left corners. They are arranged horizontally in a row below the top FNN. Each contains an identical schematic neural network drawing as the top FNN.
3. **Bottom Component:** A wide rectangular box at the base of the diagram labeled **"MNIST Dataset"** in its center.
4. **Connections:**
* **Dashed Lines (Top to Middle):** Three dashed lines emanate from the bottom edge of the top FNN box, each connecting to the top edge of one of the three subordinate FNN boxes. This indicates a flow of information, aggregation, or a master-worker relationship from the top FNN to the three below.
* **Dashed Arrows (Bottom to Middle):** Three dashed arrows point upward from the top edge of the "MNIST Dataset" box to the bottom edge of each of the three subordinate FNN boxes. This indicates that the MNIST dataset is the input source for all three lower-level FNNs.
### Detailed Analysis
* **Spatial Layout:** The diagram has a clear three-tiered structure.
* **Top Tier (Center):** One master/aggregator FNN.
* **Middle Tier (Center-Left, Center, Center-Right):** Three parallel, identical worker FNNs.
* **Bottom Tier (Center):** The shared data source (MNIST Dataset).
* **FNN Internal Structure:** Each FNN schematic shows a standard dense (fully connected) architecture. The number of nodes per layer is not specified numerically but is represented symbolically. The ellipsis (`...`) between the middle layers in each FNN indicates the presence of multiple hidden layers, suggesting these are deep neural networks.
* **Data Flow:** The arrows establish the following flow: The **MNIST Dataset** provides input to the **three parallel FNNs**. The outputs or learned representations from these three FNNs are then connected to the **single top FNN**, which likely performs a final aggregation, ensemble averaging, or meta-learning task.
### Key Observations
1. **Ensemble Architecture:** The core pattern is an ensemble of three independent FNN models (the middle tier) whose results are combined by a single higher-level FNN.
2. **Identical Sub-Models:** The three FNNs in the middle tier are visually identical, suggesting they are instances of the same model architecture, potentially trained with different initializations or on different data partitions.
3. **Shared Data Source:** All three subordinate models are trained on the same dataset (MNIST), which is a standard benchmark dataset of handwritten digits.
4. **Hierarchical Connection:** The connection from the top FNN to the three below is depicted with dashed lines, which often signifies a logical or supervisory relationship rather than a direct data pipeline in neural network diagrams.
### Interpretation
This diagram illustrates a **model ensemble or distributed learning strategy** applied to the MNIST digit classification task.
* **Purpose:** The architecture aims to improve predictive performance, robustness, or generalization by combining the knowledge of multiple FNNs. The top FNN acts as a "meta-learner" or "aggregator" that learns how to best combine the predictions or features from the three base FNNs.
* **Relationships:** The structure suggests a **two-level learning process**. The three base FNNs learn primary features directly from the raw MNIST data. The top FNN then learns a higher-order function to synthesize these base models' outputs, potentially correcting for individual model biases or errors.
* **Notable Implications:** This setup is a form of **stacked generalization** or a **committee machine**. It is designed to leverage the "wisdom of the crowd" effect, where an ensemble of models often outperforms any single constituent model. The use of the well-known MNIST dataset indicates this is likely a conceptual or pedagogical diagram explaining ensemble methods in deep learning, rather than a depiction of a novel, state-of-the-art architecture for that specific dataset. The lack of specific numerical details (layer sizes, activation functions) confirms its role as a high-level architectural schematic.