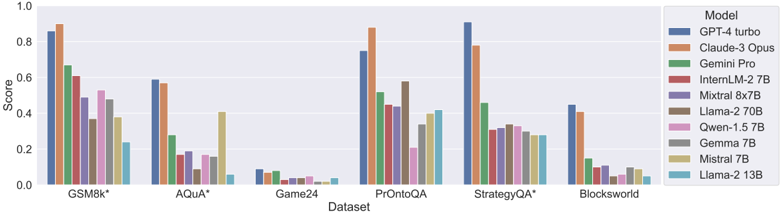
## Bar Chart: Model Performance Across Datasets
### Overview
The chart compares the performance scores of various AI models across six datasets: GSM8k*, AQuA*, Game24, PrOntoQA, StrategyQA*, and Blocksworld. Scores range from 0.0 to 1.0 on the y-axis, with datasets listed on the x-axis. The legend identifies 10 models using distinct colors.
### Components/Axes
- **X-axis (Dataset)**:
- GSM8k* (leftmost)
- AQuA*
- Game24
- PrOntoQA
- StrategyQA*
- Blocksworld (rightmost)
- **Y-axis (Score)**:
- Scale from 0.0 to 1.0 in increments of 0.2.
- **Legend (Right)**:
- Models and colors:
- Blue: GPT-4 turbo
- Orange: Claude-3 Opus
- Green: Gemini Pro
- Red: InternLM-2 7B
- Purple: Mixtral 8x7B
- Brown: Llama-2 70B
- Pink: Qwen-1.5 7B
- Gray: Gemma 7B
- Yellow: Mistral 7B
- Cyan: Llama-2 13B
### Detailed Analysis
1. **GSM8k***:
- GPT-4 turbo (blue): ~0.85
- Claude-3 Opus (orange): ~0.88
- Gemini Pro (green): ~0.65
- InternLM-2 7B (red): ~0.60
- Mixtral 8x7B (purple): ~0.50
- Llama-2 70B (brown): ~0.38
- Qwen-1.5 7B (pink): ~0.52
- Gemma 7B (gray): ~0.48
- Mistral 7B (yellow): ~0.38
- Llama-2 13B (cyan): ~0.22
2. **AQuA***:
- GPT-4 turbo: ~0.58
- Claude-3 Opus: ~0.56
- Gemini Pro: ~0.28
- InternLM-2 7B: ~0.16
- Mixtral 8x7B: ~0.18
- Llama-2 70B: ~0.08
- Qwen-1.5 7B: ~0.16
- Gemma 7B: ~0.14
- Mistral 7B: ~0.40
- Llama-2 13B: ~0.06
3. **Game24**:
- GPT-4 turbo: ~0.08
- Claude-3 Opus: ~0.04
- Gemini Pro: ~0.06
- InternLM-2 7B: ~0.02
- Mixtral 8x7B: ~0.03
- Llama-2 70B: ~0.03
- Qwen-1.5 7B: ~0.04
- Gemma 7B: ~0.02
- Mistral 7B: ~0.01
- Llama-2 13B: ~0.02
4. **PrOntoQA**:
- GPT-4 turbo: ~0.75
- Claude-3 Opus: ~0.85
- Gemini Pro: ~0.50
- InternLM-2 7B: ~0.45
- Mixtral 8x7B: ~0.45
- Llama-2 70B: ~0.58
- Qwen-1.5 7B: ~0.20
- Gemma 7B: ~0.35
- Mistral 7B: ~0.40
- Llama-2 13B: ~0.42
5. **StrategyQA***:
- GPT-4 turbo: ~0.90
- Claude-3 Opus: ~0.78
- Gemini Pro: ~0.45
- InternLM-2 7B: ~0.30
- Mixtral 8x7B: ~0.32
- Llama-2 70B: ~0.33
- Qwen-1.5 7B: ~0.32
- Gemma 7B: ~0.30
- Mistral 7B: ~0.28
- Llama-2 13B: ~0.28
6. **Blocksworld**:
- GPT-4 turbo: ~0.45
- Claude-3 Opus: ~0.40
- Gemini Pro: ~0.14
- InternLM-2 7B: ~0.08
- Mixtral 8x7B: ~0.10
- Llama-2 70B: ~0.04
- Qwen-1.5 7B: ~0.06
- Gemma 7B: ~0.08
- Mistral 7B: ~0.08
- Llama-2 13B: ~0.04
### Key Observations
- **High Performance**: GPT-4 turbo and Claude-3 Opus dominate most datasets, with scores often exceeding 0.7.
- **Low Performance**: Game24 shows near-zero scores for most models, except Mistral 7B (~0.01) and Llama-2 13B (~0.02).
- **Mid-Range Models**: Gemini Pro, InternLM-2 7B, and Mixtral 8x7B cluster between 0.3–0.5 across datasets.
- **Smaller Models**: Llama-2 70B, Qwen-1.5 7B, and Mistral 7B generally underperform larger models but show variability (e.g., Mistral 7B outperforms others on AQuA*).
### Interpretation
The chart suggests that larger models (e.g., GPT-4 turbo, Claude-3 Opus) consistently achieve higher scores, indicating superior generalization across tasks. However, exceptions like Mistral 7B on AQuA* (~0.40) and Llama-2 13B on PrOntoQA (~0.42) highlight dataset-specific strengths. The near-zero scores on Game24 imply this dataset poses unique challenges, possibly requiring specialized training. The data underscores a correlation between model size and performance but also reveals niche capabilities in smaller models for specific tasks.