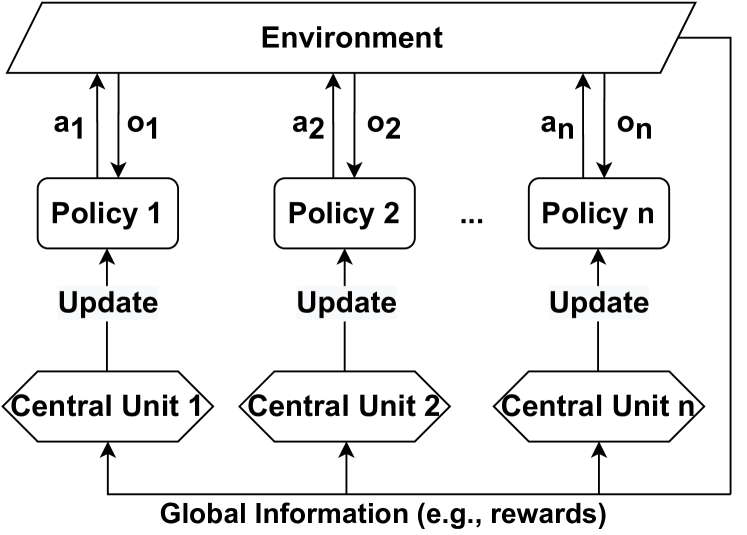
## Diagram: Multi-Agent Reinforcement Learning Architecture
### Overview
The image depicts a multi-agent reinforcement learning architecture. It illustrates how multiple policies interact with an environment and are updated based on global information. The diagram shows the flow of actions and observations between the environment and the policies, as well as the update mechanism involving central units and global information.
### Components/Axes
* **Environment:** Represented as a rounded rectangle at the top of the diagram.
* **Policies:** "Policy 1", "Policy 2", ..., "Policy n". Represented as rounded rectangles.
* **Central Units:** "Central Unit 1", "Central Unit 2", ..., "Central Unit n". Represented as diamond shapes.
* **Actions:** "a1", "a2", ..., "an". Arrows pointing from the policies to the environment.
* **Observations:** "o1", "o2", ..., "on". Arrows pointing from the environment to the policies.
* **Update:** Text labels indicating the update process from the central units to the policies.
* **Global Information:** "Global Information (e.g., rewards)". Text label at the bottom, with arrows pointing from it to each central unit.
### Detailed Analysis
* **Environment:** The environment interacts with multiple policies.
* **Policies:** There are 'n' policies, each labeled "Policy 1", "Policy 2", and so on, up to "Policy n".
* **Actions and Observations:** Each policy sends an action (a1, a2, ..., an) to the environment and receives an observation (o1, o2, ..., on) from the environment. The arrows indicate the direction of information flow.
* **Central Units:** Each policy is associated with a central unit (Central Unit 1, Central Unit 2, ..., Central Unit n).
* **Update Mechanism:** The central units update the policies.
* **Global Information:** All central units receive global information, such as rewards, which is used to update the policies.
### Key Observations
* The diagram illustrates a decentralized approach where each policy interacts directly with the environment.
* The central units facilitate the update process, likely based on the global information received.
* The architecture supports multiple agents (policies) learning simultaneously.
### Interpretation
The diagram represents a common architecture for multi-agent reinforcement learning. Each agent (policy) acts in the environment and receives observations. The central units likely aggregate information or perform computations to provide update signals to the policies. The global information, such as rewards, is crucial for coordinating the learning process across multiple agents. This architecture allows for distributed learning and can be applied to various multi-agent scenarios, such as robotics, game playing, and resource management. The use of global information suggests a cooperative or coordinated learning approach, where agents aim to optimize a shared objective.