\n
## Diagram: Multi-Agent System with Centralized Learning
### Overview
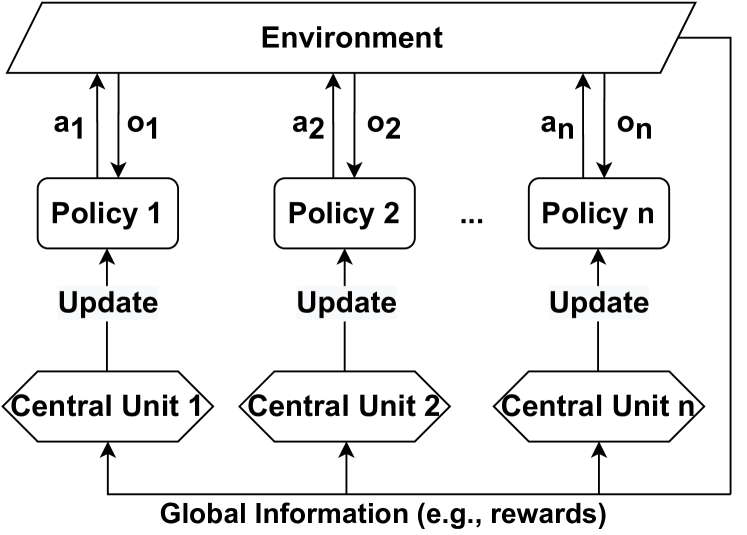
The image depicts a diagram of a multi-agent reinforcement learning system. It illustrates the interaction between multiple policies, a shared environment, and central units responsible for updating the policies based on global information. The diagram shows a cyclical flow of information between these components.
### Components/Axes
The diagram consists of the following components:
* **Environment:** A large, grey rectangle at the top, labeled "Environment".
* **Policies:** 'n' number of rectangular boxes labeled "Policy 1", "Policy 2", ..., "Policy n". These are arranged in a row below the Environment.
* **Central Units:** 'n' number of diamond-shaped boxes labeled "Central Unit 1", "Central Unit 2", ..., "Central Unit n". These are arranged in a row below the Policies.
* **Arrows:** Arrows indicate the flow of information between the components.
* **Labels on Arrows:**
* `a1`, `a2`, ..., `an`: Actions taken by each policy.
* `o1`, `o2`, ..., `on`: Observations received by each policy.
* "Update": Indicates the update signal from the Central Units to the Policies.
* "Global Information (e.g., rewards)": Label at the bottom, indicating the information shared between Central Units.
### Detailed Analysis or Content Details
The diagram illustrates the following information flow:
1. **Environment to Policies:** The Environment provides observations (`o1`, `o2`, ..., `on`) to each Policy.
2. **Policies to Environment:** Each Policy takes an action (`a1`, `a2`, ..., `an`) that affects the Environment.
3. **Policies to Central Units:** Each Policy sends information to its corresponding Central Unit.
4. **Central Units to Policies:** Each Central Unit sends an "Update" signal to its corresponding Policy.
5. **Central Units to Central Units:** All Central Units receive "Global Information (e.g., rewards)" and communicate with each other.
The diagram suggests a decentralized execution of policies within a centralized learning framework. Each policy operates independently within the environment, but their updates are coordinated by the central units based on global information.
### Key Observations
* The diagram highlights a clear separation between policy execution and policy learning.
* The "Global Information" suggests a shared reward structure or a common objective for all agents.
* The cyclical nature of the diagram indicates an iterative learning process.
* The use of 'n' suggests a scalable system capable of handling an arbitrary number of agents.
### Interpretation
This diagram represents a common architecture in multi-agent reinforcement learning, specifically a centralized training with decentralized execution (CTDE) paradigm. The environment represents the world in which the agents operate. Each policy represents the decision-making process of an individual agent. The central units act as a centralized learner, aggregating information from all agents and providing updates to improve their policies. The global information allows the central units to coordinate the agents' learning process, potentially leading to more efficient and effective learning.
The diagram suggests that the system aims to leverage the benefits of both decentralized execution (allowing for scalability and robustness) and centralized learning (allowing for better coordination and information sharing). The "e.g., rewards" in the global information label indicates that the central units likely use a shared reward signal to guide the learning process. This architecture is particularly useful in scenarios where agents need to cooperate or compete to achieve a common goal.