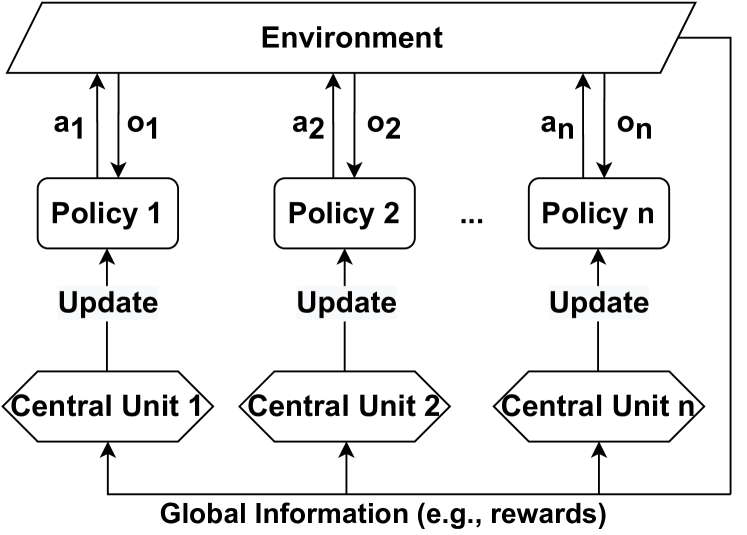
## Flowchart: Decentralized Policy-Environment Interaction System
### Overview
The diagram illustrates a decentralized system where multiple policies interact with an environment, update central units, and contribute to global information. The structure emphasizes scalability (denoted by "n") and bidirectional information flow between policies, central units, and the environment.
### Components/Axes
1. **Environment**: Topmost rectangular box labeled "Environment."
2. **Policies**:
- Labeled "Policy 1," "Policy 2," ..., "Policy n" (horizontal sequence).
- Each policy has:
- Inputs from the environment: `a1, a2, ..., an` (leftward arrows).
- Outputs to the environment: `o1, o2, ..., on` (rightward arrows).
3. **Central Units**:
- Labeled "Central Unit 1," "Central Unit 2," ..., "Central Unit n" (horizontal sequence below policies).
- Each central unit receives:
- "Update" signals from its corresponding policy (upward arrows).
- "Global Information" (e.g., rewards) from a shared pool (upward arrows).
4. **Arrows**:
- Black arrows denote information flow direction.
- Labels: "Update" (policy→central unit), "Global Information" (central unit→shared pool).
### Detailed Analysis
- **Environment**: Acts as the external interface, providing inputs (`a_i`) and receiving outputs (`o_i`) from policies.
- **Policy-Central Unit Loop**: Each policy processes environmental inputs, generates outputs, and sends updates to its dedicated central unit.
- **Global Information Aggregation**: Central units collectively contribute to a shared "Global Information" pool, suggesting coordination or resource sharing.
### Key Observations
1. **Scalability**: The use of "n" implies the system can expand horizontally (more policies/central units).
2. **Decentralized Control**: Policies operate independently but contribute to a centralized information pool.
3. **Bidirectional Flow**: Environment-policy interaction is two-way (inputs/outputs), while central units aggregate information unidirectionally.
### Interpretation
This diagram represents a **multi-agent reinforcement learning (MARL)** or **distributed control system** architecture. Policies act as autonomous agents in the environment, while central units may represent coordination mechanisms (e.g., parameter servers, consensus algorithms). The "Global Information" pool likely serves as a shared reward or state representation, enabling policies to learn collaboratively while maintaining decentralized decision-making. The absence of explicit numerical values suggests a conceptual framework rather than a quantitative model.