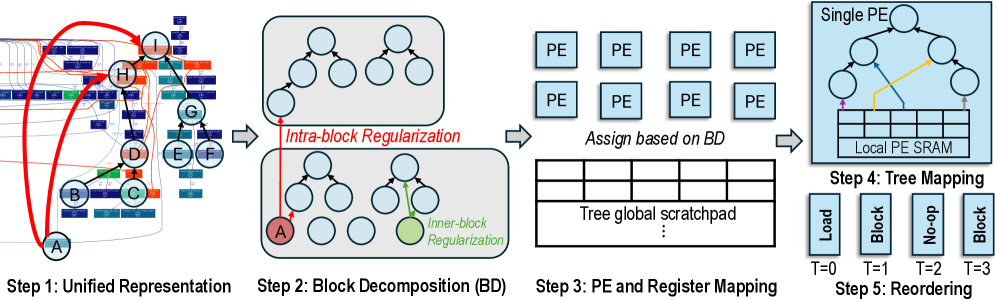
## Diagram: Unified Representation to Reordering
### Overview
The image is a diagram illustrating a five-step process, starting with a unified representation and ending with reordering. Each step is visually represented with diagrams and labels, showing the transformation of data and processes involved.
### Components/Axes
* **Step 1: Unified Representation:** Shows a complex network of nodes (A, B, C, D, E, F, G, H, I) and connections.
* **Step 2: Block Decomposition (BD):** Illustrates the decomposition of the network into blocks with "Intra-block Regularization" and "Inner-block Regularization" highlighted.
* **Step 3: PE and Register Mapping:** Depicts the assignment of blocks to Processing Elements (PEs) and a "Tree global scratchpad".
* **Step 4: Tree Mapping:** Shows a single PE with a tree structure mapped to a "Local PE SRAM".
* **Step 5: Reordering:** Represents the reordering process with labels "Load", "Block", "No-op", and "Block" at time steps T=0, T=1, T=2, and T=3 respectively.
### Detailed Analysis
* **Step 1: Unified Representation:**
* Node A is at the bottom-left.
* Nodes B and C are slightly above and to the right of A.
* Node D is above B and C.
* Nodes E, F, and G are to the right of D.
* Nodes H and I are at the top, with H to the left of I.
* Red arrows indicate connections from A to H and I, and from H to I.
* **Step 2: Block Decomposition (BD):**
* Two blocks are shown, each containing a tree structure.
* The top block shows two trees.
* The bottom block shows a tree and a few individual nodes.
* A red arrow labeled "Intra-block Regularization" connects node A (colored red) from Step 1 to the top tree.
* A green arrow labeled "Inner-block Regularization" connects a node within the bottom block (colored green) to the top of the tree in the bottom block.
* **Step 3: PE and Register Mapping:**
* An array of 8 "PE" blocks is shown.
* The text "Assign based on BD" is below the PE array.
* A table labeled "Tree global scratchpad" is shown below the assignment instruction.
* **Step 4: Tree Mapping:**
* A "Single PE" block is shown.
* A tree structure is mapped to a "Local PE SRAM".
* Arrows indicate data flow within the PE.
* **Step 5: Reordering:**
* Four blocks are labeled "Load", "Block", "No-op", and "Block".
* These blocks correspond to time steps T=0, T=1, T=2, and T=3 respectively.
### Key Observations
* The diagram illustrates a multi-step process for mapping a unified representation onto processing elements.
* Block decomposition and regularization are key steps in the process.
* The final step involves reordering operations for efficient execution.
### Interpretation
The diagram outlines a process for optimizing the execution of a complex task on parallel processing elements. The initial unified representation is decomposed into blocks, which are then assigned to PEs. Regularization techniques are applied to improve the structure of the blocks. The tree mapping step maps the computational structure onto the local memory of each PE. Finally, the reordering step optimizes the sequence of operations for efficient execution. The process aims to leverage parallel processing to accelerate the execution of the task.