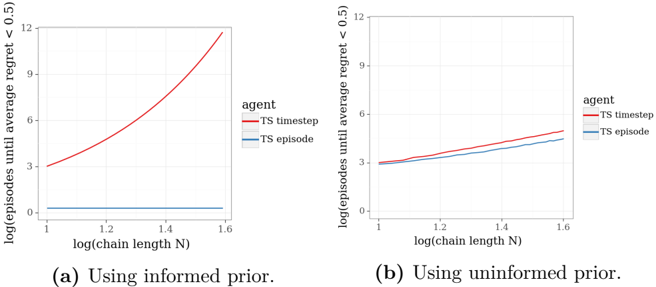
## Line Charts: Performance of Thompson Sampling Agents with Different Priors
### Overview
The image contains two side-by-side line charts comparing the performance of two reinforcement learning agents ("TS timestep" and "TS episode") under different prior conditions. The charts plot the number of episodes required to achieve a low average regret against the logarithm of the chain length (N). The left chart (a) shows results using an "informed prior," while the right chart (b) shows results using an "uninformed prior."
### Components/Axes
* **Chart Type:** Two line charts with logarithmic axes.
* **Sub-captions:**
* (a) Using informed prior.
* (b) Using uninformed prior.
* **X-Axis (Both Charts):** Label: `log(chain length N)`. Scale: Linear from 1 to 1.6, with major ticks at 1, 1.2, 1.4, and 1.6.
* **Y-Axis (Both Charts):** Label: `log(episodes until average regret < 0.5)`. Scale: Linear from 0 to 12, with major ticks at 0, 3, 6, 9, and 12.
* **Legend (Both Charts):** Positioned to the right of the plot area.
* Title: `agent`
* Red line: `TS timestep`
* Blue line: `TS episode`
### Detailed Analysis
**Chart (a): Using informed prior.**
* **Trend Verification:**
* **TS timestep (Red Line):** Shows a strong, accelerating upward curve. The slope increases as the x-value increases.
* **TS episode (Blue Line):** Appears as a nearly horizontal, flat line very close to the bottom of the chart.
* **Approximate Data Points:**
* At `log(chain length N) = 1.0`: Red ≈ 3.0, Blue ≈ 0.5.
* At `log(chain length N) = 1.2`: Red ≈ 4.5, Blue ≈ 0.5.
* At `log(chain length N) = 1.4`: Red ≈ 7.5, Blue ≈ 0.5.
* At `log(chain length N) = 1.6`: Red ≈ 12.0, Blue ≈ 0.5.
**Chart (b): Using uninformed prior.**
* **Trend Verification:**
* **TS timestep (Red Line):** Shows a steady, linear upward trend.
* **TS episode (Blue Line):** Also shows a steady, linear upward trend, but with a slightly shallower slope than the red line.
* **Approximate Data Points:**
* At `log(chain length N) = 1.0`: Red ≈ 3.0, Blue ≈ 3.0.
* At `log(chain length N) = 1.2`: Red ≈ 3.8, Blue ≈ 3.5.
* At `log(chain length N) = 1.4`: Red ≈ 4.5, Blue ≈ 4.0.
* At `log(chain length N) = 1.6`: Red ≈ 5.2, Blue ≈ 4.5.
### Key Observations
1. **Dramatic Prior Effect on "TS timestep":** The performance of the "TS timestep" agent is radically different between the two priors. With an informed prior (a), its required episodes grow super-linearly (exponentially on this log-log plot) with chain length. With an uninformed prior (b), the growth is linear.
2. **Robustness of "TS episode":** The "TS episode" agent's performance is far less sensitive to the prior. With an informed prior (a), it performs exceptionally well and is invariant to chain length (flat line). With an uninformed prior (b), it performs similarly to "TS timestep" but slightly better (lower line).
3. **Crossover in Performance:** In the informed prior scenario (a), "TS episode" vastly outperforms "TS timestep" for all chain lengths shown. In the uninformed prior scenario (b), the two agents have very similar performance, with "TS episode" maintaining a slight, consistent advantage.
4. **Scale of Difference:** The y-axis represents a logarithmic scale. Therefore, the difference in chart (a) is enormous. At `log(N)=1.6`, "TS timestep" requires approximately `10^12` episodes (since log10(12) ≈ 12), while "TS episode" requires only about `10^0.5 ≈ 3` episodes.
### Interpretation
This data demonstrates a critical interaction between an agent's update rule and the quality of its prior knowledge in a sequential decision-making task (likely a multi-armed bandit or reinforcement learning problem with chain-structured state or action spaces).
* **"TS timestep" (likely Thompson Sampling updated every timestep)** is highly dependent on a good prior. An incorrect or uninformed prior leads to catastrophic sample inefficiency as the problem complexity (chain length N) grows. Its performance degrades severely with scale when the prior is not informative.
* **"TS episode" (likely Thompson Sampling updated once per episode)** is remarkably robust. It can leverage an informative prior to achieve near-constant-time learning regardless of chain length. Even with no prior knowledge, it scales gracefully and linearly, matching or beating the timestep-based approach.
* **The underlying message** suggests that for problems with long temporal horizons or deep structure (like chains), aggregating information at the episode level ("TS episode") provides a crucial regularization effect. It prevents the rapid, potentially misguided belief updates that can occur with timestep-based sampling, especially when the initial prior is wrong. This makes "TS episode" a more reliable and scalable choice in practice when prior knowledge is uncertain. The charts serve as a strong empirical argument for the importance of update frequency in Bayesian exploration algorithms.