## Line Chart: Model Performance vs Context Length
### Overview
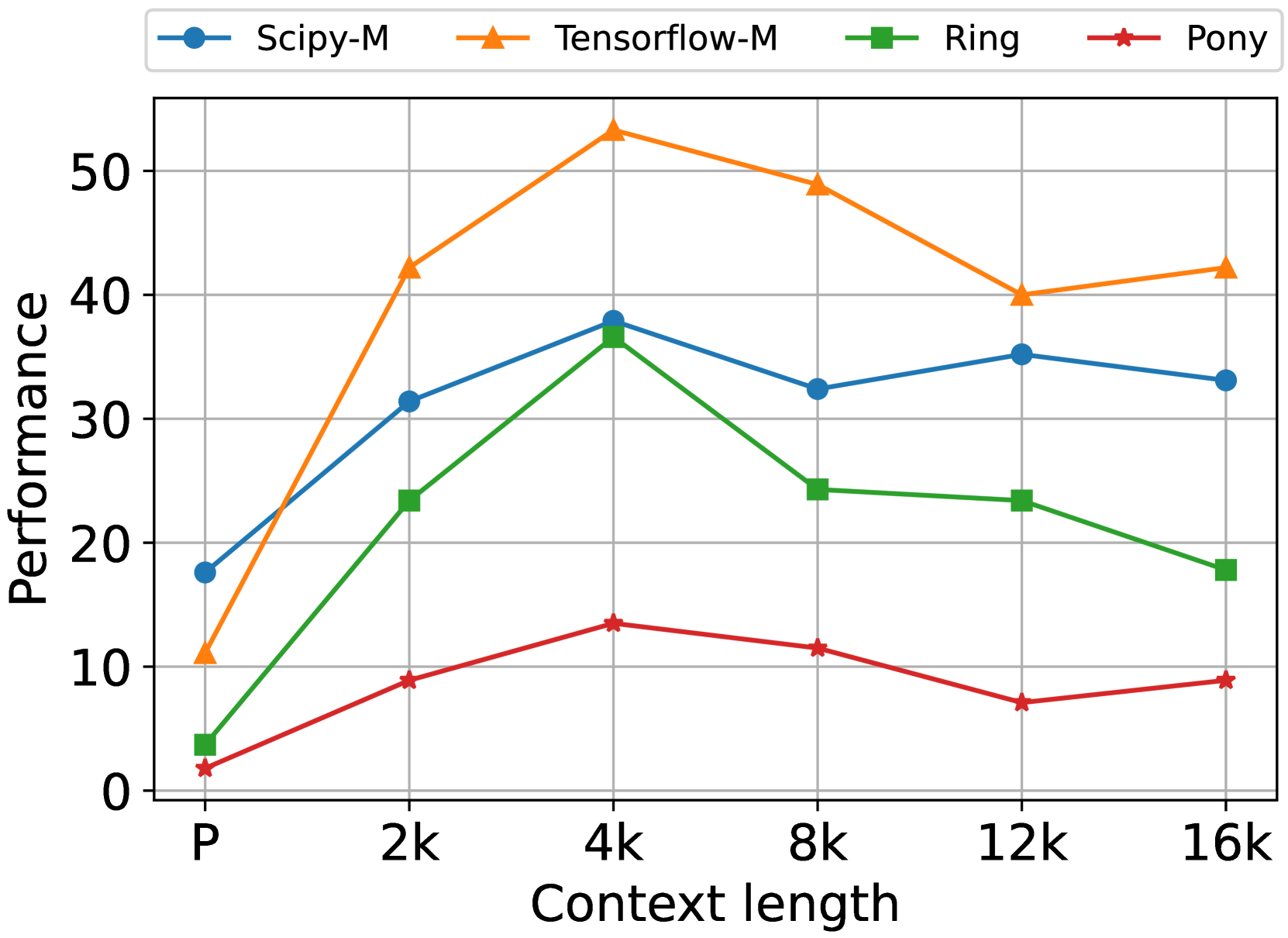
The chart compares the performance of four computational models (Scipy-M, Tensorflow-M, Ring, Pony) across varying context lengths (P, 2k, 4k, 8k, 12k, 16k). Performance is measured on a scale from 0 to 50, with distinct color-coded lines and markers for each model.
### Components/Axes
- **X-axis (Context length)**: Labeled with markers "P", "2k", "4k", "8k", "12k", "16k".
- **Y-axis (Performance)**: Scaled from 0 to 50.
- **Legend**: Located in the top-left corner, mapping:
- Blue circles: Scipy-M
- Orange triangles: Tensorflow-M
- Green squares: Ring
- Red stars: Pony
### Detailed Analysis
1. **Scipy-M (Blue Circles)**:
- Starts at ~18 (P), rises to ~38 (4k), dips to ~32 (8k), peaks at ~35 (12k), then declines to ~33 (16k).
- Shows moderate volatility with a clear peak at 4k.
2. **Tensorflow-M (Orange Triangles)**:
- Begins at ~10 (P), surges to ~42 (2k), peaks at ~53 (4k), then declines to ~49 (8k), ~40 (12k), and ~42 (16k).
- Dominates performance, especially at 4k, with a sharp rise and gradual decline.
3. **Ring (Green Squares)**:
- Starts at ~3 (P), climbs to ~23 (2k), peaks at ~37 (4k), then drops to ~24 (8k), ~23 (12k), and ~18 (16k).
- Mirrors Scipy-M’s trend but with lower absolute values.
4. **Pony (Red Stars)**:
- Begins at ~1 (P), rises to ~9 (2k), peaks at ~13 (4k), then declines to ~11 (8k), ~7 (12k), and ~9 (16k).
- Consistently the lowest performer, with a modest peak at 4k.
### Key Observations
- **Tensorflow-M** achieves the highest performance across all context lengths, with a pronounced peak at 4k (~53).
- **Scipy-M** and **Ring** exhibit similar trends but with Scipy-M outperforming Ring by ~5–10 units at equivalent context lengths.
- **Pony** lags significantly, with performance remaining below 15 for most context lengths.
- All models show a performance peak at 4k, followed by declines, suggesting diminishing returns or computational bottlenecks at higher context lengths.
### Interpretation
The data suggests Tensorflow-M is optimized for mid-range context lengths (4k), where it achieves peak efficiency. Scipy-M and Ring demonstrate comparable scaling but with lower absolute performance, possibly due to architectural differences. Pony’s consistently low performance may indicate suboptimal resource utilization or algorithmic limitations. The universal decline after 4k hints at shared constraints (e.g., memory, processing power) across models when handling larger context lengths. This chart could inform model selection based on context length requirements, with Tensorflow-M being the most robust choice for mid-sized tasks.