\n
## Line Chart: Performance vs. Context Length
### Overview
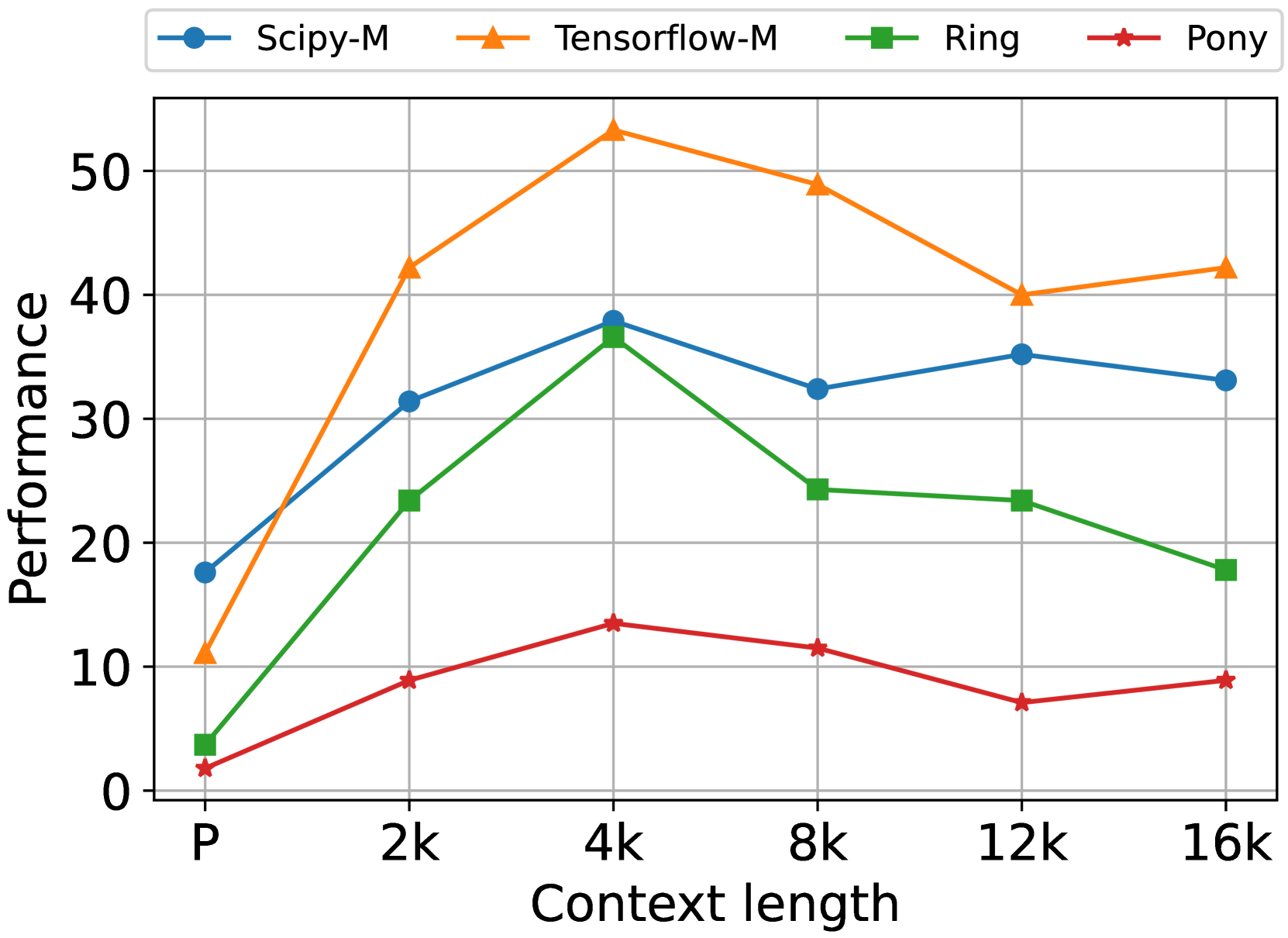
This line chart displays the performance of four different models (Scipy-M, Tensorflow-M, Ring, and Pony) across varying context lengths. The x-axis represents context length, and the y-axis represents performance. The chart illustrates how performance changes as the context length increases for each model.
### Components/Axes
* **X-axis Title:** Context length
* **X-axis Markers:** P, 2k, 4k, 8k, 12k, 16k
* **Y-axis Title:** Performance
* **Y-axis Scale:** 0 to 60 (approximately)
* **Legend:** Located at the top-center of the chart.
* Scipy-M (Blue line with circle markers)
* Tensorflow-M (Orange line with triangle markers)
* Ring (Green line with square markers)
* Pony (Red line with star markers)
### Detailed Analysis
**Scipy-M (Blue):** The line slopes upward initially, reaches a peak around 4k context length, and then plateaus.
* P: ~18
* 2k: ~31
* 4k: ~35
* 8k: ~33
* 12k: ~34
* 16k: ~35
**Tensorflow-M (Orange):** The line exhibits a strong upward trend from P to 4k, then declines slightly.
* P: ~12
* 2k: ~25
* 4k: ~54
* 8k: ~50
* 12k: ~45
* 16k: ~42
**Ring (Green):** The line increases sharply from P to 2k, then plateaus and declines slightly.
* P: ~3
* 2k: ~23
* 4k: ~25
* 8k: ~24
* 12k: ~23
* 16k: ~18
**Pony (Red):** The line shows a slight increase from P to 4k, then declines and remains relatively stable.
* P: ~5
* 2k: ~8
* 4k: ~14
* 8k: ~10
* 12k: ~7
* 16k: ~9
### Key Observations
* Tensorflow-M demonstrates the highest performance overall, peaking at a context length of 4k.
* Scipy-M shows a consistent performance level after 4k context length.
* Ring experiences a rapid initial performance increase, but its performance plateaus and then declines.
* Pony consistently exhibits the lowest performance among the four models.
* There is a clear trend of diminishing returns for Tensorflow-M and Ring as context length increases beyond 4k.
### Interpretation
The chart suggests that Tensorflow-M is the most effective model for this task, particularly when using context lengths up to 4k. Scipy-M provides a stable performance level, while Ring shows a strong initial gain but doesn't scale well with increasing context length. Pony consistently underperforms. The diminishing returns observed for Tensorflow-M and Ring beyond 4k suggest that increasing context length beyond this point does not significantly improve performance and may even lead to a slight decrease. This could be due to factors such as computational limitations or the models' inability to effectively utilize longer context windows. The differences in performance between the models likely reflect variations in their architectures, training data, or optimization strategies. The chart provides valuable insights into the trade-offs between context length and performance for each model, which can inform decisions about model selection and hyperparameter tuning.