\n
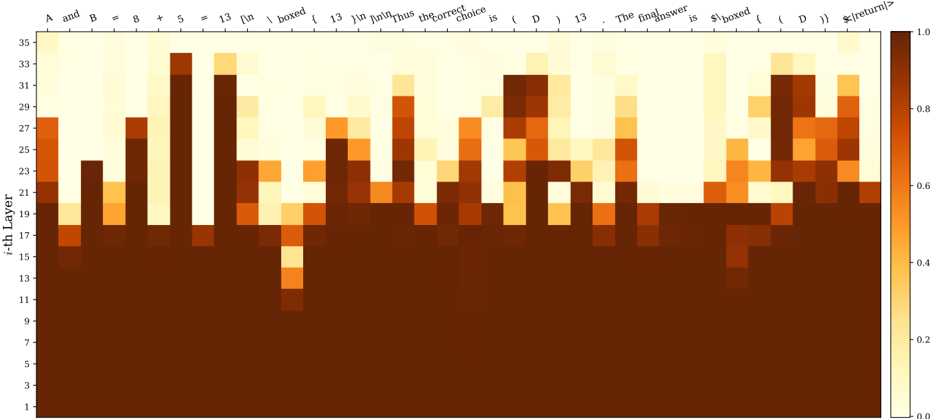
## Heatmap: Activation Values Across Layers and Tokens
### Overview
The image presents a heatmap visualizing activation values across different layers of a model and various tokens. The heatmap displays the intensity of activation, ranging from 0.0 to 1.0, with darker colors representing lower activation and lighter colors representing higher activation. The x-axis represents tokens, and the y-axis represents the i-th layer.
### Components/Axes
* **X-axis (Tokens):** Labels include: "A and B =", "8 + 5 =", "13 [in", "boxed", "f 13", "Thus", "the_correct", "choice", "is", "( D )", "13", "The", "finalanswer", "is", "$boxed", "f ( D )", "$return)".
* **Y-axis (i-th Layer):** Ranges from 1 to 35, with markers at integer values. Labeled as "i-th Layer".
* **Color Scale (Right):** Represents activation values. Ranges from 0.0 (dark brown) to 1.0 (light yellow). Markers at 0.0, 0.2, 0.4, 0.6, 0.8, and 1.0.
### Detailed Analysis
The heatmap shows varying activation levels for each token across the different layers. Here's a breakdown of observed activation patterns:
* **"A and B =":** Shows moderate activation (approximately 0.4-0.6) primarily in layers 21-27.
* **"8 + 5 =":** Displays a peak in activation (reaching approximately 0.8-0.9) around layers 25-30.
* **"13 [in":** Shows moderate activation (approximately 0.4-0.6) in layers 15-25.
* **"boxed":** Displays a peak in activation (reaching approximately 0.9-1.0) around layers 28-33.
* **"f 13":** Shows moderate activation (approximately 0.4-0.6) in layers 15-25.
* **"Thus":** Displays a peak in activation (reaching approximately 0.8-0.9) around layers 28-33.
* **"the_correct":** Shows moderate activation (approximately 0.4-0.6) in layers 15-25.
* **"choice":** Displays a peak in activation (reaching approximately 0.9-1.0) around layers 28-33.
* **"is":** Shows moderate activation (approximately 0.4-0.6) in layers 15-25.
* **"( D )":** Displays a peak in activation (reaching approximately 0.8-0.9) around layers 28-33.
* **"13":** Shows moderate activation (approximately 0.4-0.6) in layers 15-25.
* **"The":** Displays a peak in activation (reaching approximately 0.8-0.9) around layers 28-33.
* **"finalanswer":** Shows moderate activation (approximately 0.4-0.6) in layers 15-25.
* **"is":** Displays a peak in activation (reaching approximately 0.8-0.9) around layers 28-33.
* **"$boxed":** Shows moderate activation (approximately 0.4-0.6) in layers 15-25.
* **"f ( D )":** Displays a peak in activation (reaching approximately 0.8-0.9) around layers 28-33.
* **"$return)":** Shows moderate activation (approximately 0.4-0.6) in layers 15-25.
Generally, activation values are lower in the initial layers (1-15) and tend to increase towards the higher layers (25-35), particularly for tokens like "boxed", "Thus", "choice", "( D )", "The", and "$boxed".
### Key Observations
* Tokens like "boxed", "Thus", "choice", "( D )", "The", and "$boxed" consistently exhibit higher activation values in the deeper layers (28-33).
* The activation patterns are not uniform across all tokens; some tokens show more sustained activation across multiple layers, while others have more localized peaks.
* The lower layers (1-15) generally show lower activation values across all tokens.
### Interpretation
This heatmap likely represents the internal state of a neural network processing a mathematical or logical problem. The tokens represent parts of an input sequence, and the layers represent successive stages of processing. The activation values indicate the degree to which each token contributes to the network's internal representation at each layer.
The higher activation values in the deeper layers for tokens like "boxed" and "Thus" suggest that these tokens are crucial for the network's final decision or output. The network appears to be building up its understanding of the problem as it progresses through the layers, with the later layers focusing on the most relevant information.
The relatively low activation in the initial layers suggests that these layers are responsible for more basic feature extraction, while the deeper layers perform more complex reasoning and inference. The varying activation patterns across tokens indicate that the network is not treating all tokens equally; it is selectively focusing on the most important parts of the input sequence.
The heatmap provides insights into the network's internal workings and can be used to understand how it arrives at its conclusions. It could be used for debugging, model analysis, or feature engineering.