## Bar Chart: Adder: Time vs Core count
### Overview
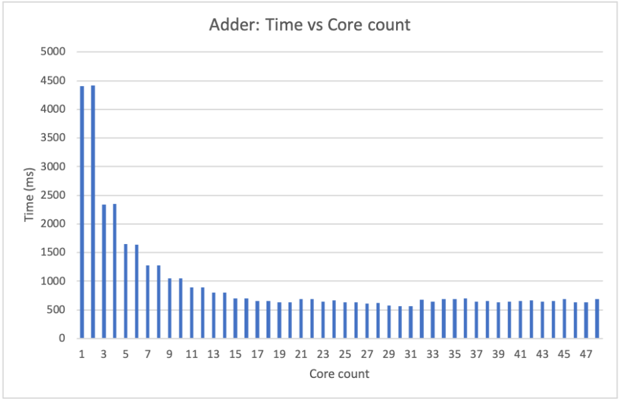
The chart visualizes the relationship between computational core count (x-axis) and execution time in milliseconds (y-axis) for an "Adder" operation. Time decreases as core count increases, with a notable plateau after a certain core threshold.
### Components/Axes
- **Title**: "Adder: Time vs Core count"
- **X-axis (Core count)**:
- Labels: Odd integers from 1 to 47 (1, 3, 5, ..., 47)
- Scale: Discrete increments of 2 cores (e.g., 1, 3, 5, ..., 47)
- **Y-axis (Time (ms))**:
- Labels: 0, 500, 1000, 1500, 2000, 2500, 3000, 3500, 4000, 4500, 5000
- Scale: Linear increments of 500 ms
- **Bars**:
- Color: Blue (no legend present)
- Height: Proportional to execution time
### Detailed Analysis
- **Core 1 & 3**: Highest execution times (~4400 ms each), indicating sequential processing dominates at low core counts.
- **Core 5**: Time drops to ~2300 ms, showing initial parallelization benefits.
- **Core 7-9**: Further reduction to ~1300 ms, with minor fluctuations.
- **Core 11**: Time stabilizes at ~900 ms, marking a plateau.
- **Core 13-47**: Execution time remains relatively flat (~600-700 ms), with slight variations (e.g., ~650 ms at core 15, ~600 ms at core 31).
### Key Observations
1. **Diminishing Returns**: Time reduction slows significantly after core 11, suggesting parallelization overhead or algorithmic limitations.
2. **Odd-Numbered Cores**: All core counts are odd, possibly reflecting test case design constraints.
3. **Stability**: Post-core 11, time varies minimally (±50 ms), indicating saturation of performance gains.
### Interpretation
The data demonstrates that increasing core count reduces computation time for the Adder operation up to ~11 cores, after which parallelization efficiency plateaus. This aligns with Amdahl's Law, where sequential bottlenecks limit scalability. The odd-numbered core counts may reflect hardware/software constraints (e.g., thread grouping). The plateau suggests that beyond 11 cores, adding more resources yields negligible time savings, highlighting the need for algorithmic optimization or hybrid parallel-sequential approaches for larger core counts.