## Diagram: Multi-Policy Reinforcement Learning
### Overview
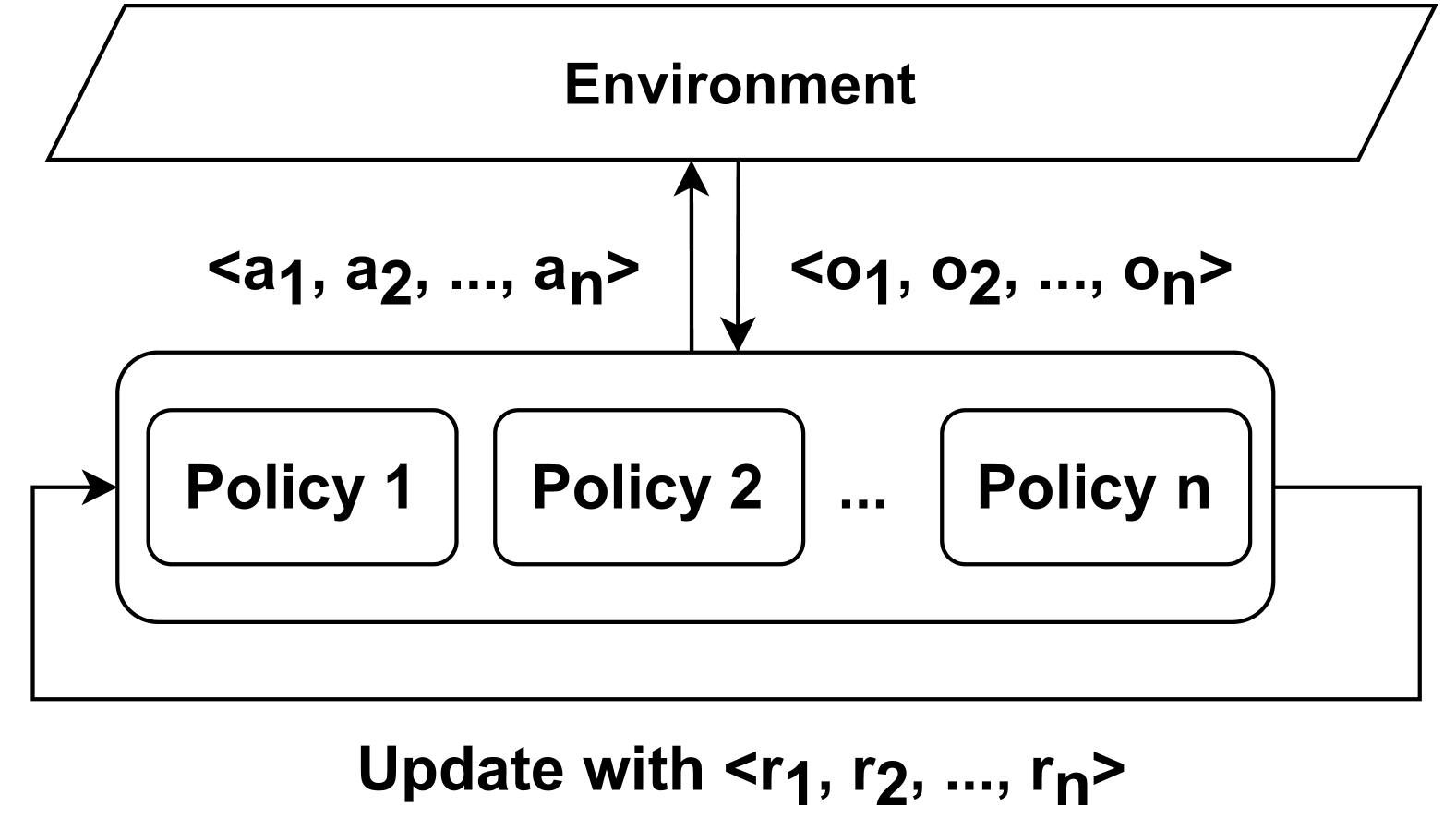
The image is a diagram illustrating a multi-policy reinforcement learning system. It shows the interaction between an environment and a set of policies, with updates based on rewards received.
### Components/Axes
* **Environment:** A trapezoidal shape at the top, representing the external environment.
* **Policies:** Three rounded rectangles labeled "Policy 1", "Policy 2", and "Policy n", representing individual policies. An ellipsis ("...") indicates that there may be more policies between Policy 2 and Policy n.
* **Actions:** An arrow pointing from the policies to the environment, labeled "<a1, a2, ..., an>", representing the actions taken by the policies.
* **Observations:** An arrow pointing from the environment to the policies, labeled "<o1, o2, ..., on>", representing the observations received from the environment.
* **Rewards:** An arrow looping from "Policy n" back to "Policy 1", labeled "Update with <r1, r2, ..., rn>", representing the rewards used to update the policies.
### Detailed Analysis
* **Environment:** The environment is the external system with which the policies interact.
* **Policies:** The policies are the decision-making components of the system. Each policy takes actions based on observations and receives rewards.
* **Actions:** The actions are the outputs of the policies, which affect the environment. The actions are represented as a sequence a1, a2, ..., an.
* **Observations:** The observations are the inputs to the policies, which provide information about the environment. The observations are represented as a sequence o1, o2, ..., on.
* **Rewards:** The rewards are the feedback signals that the policies use to learn. The rewards are represented as a sequence r1, r2, ..., rn. The rewards are used to update the policies, presumably to improve their performance.
### Key Observations
* The diagram shows a closed-loop system, where the policies interact with the environment, receive feedback, and update their behavior.
* The system has multiple policies, which suggests that it may be designed to handle complex tasks or environments.
* The use of sequences for actions, observations, and rewards suggests that the system may be dealing with time-series data or sequential decision-making problems.
### Interpretation
The diagram illustrates a multi-policy reinforcement learning system, where multiple policies interact with an environment, receive observations, take actions, and receive rewards. The rewards are used to update the policies, allowing them to learn and improve their performance over time. This type of system is often used in complex environments where a single policy may not be sufficient to achieve the desired goals. The diagram highlights the key components and interactions of such a system, providing a high-level overview of its architecture and functionality.