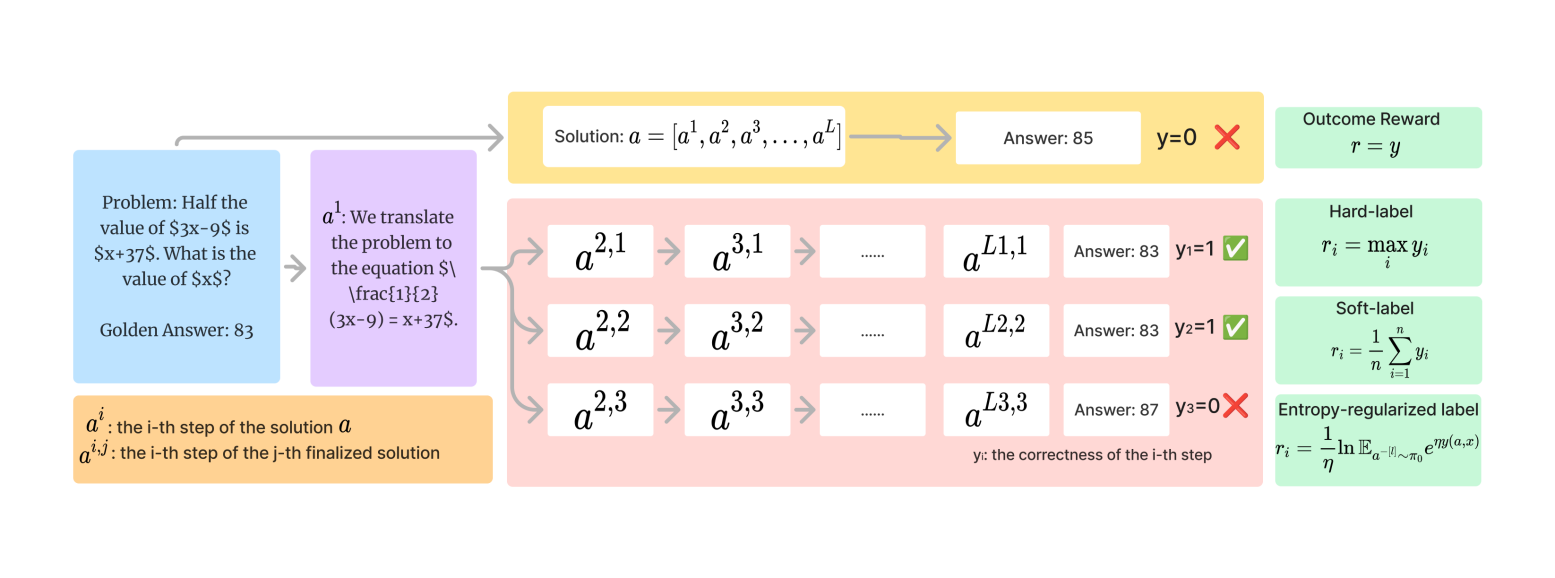
## Diagram: Step-wise Solution Generation and Reward Calculation Process
### Overview
The image is a technical flowchart illustrating a process for solving a mathematical word problem through multiple solution paths, evaluating the correctness of each step, and applying different reward mechanisms. It appears to be a conceptual diagram for a machine learning or AI training framework, likely related to reinforcement learning or step-wise reasoning.
### Components/Axes
The diagram is organized into three main vertical sections, flowing from left to right.
**1. Left Section (Problem & Initial Translation):**
* **Blue Box (Top-Left):** Contains the initial problem statement and the "Golden Answer."
* Text: "Problem: Half the value of $3x-9$ is $x+37$. What is the value of $x$?"
* Text: "Golden Answer: 83"
* **Purple Box (Center-Left):** Shows the first step of translating the word problem into a mathematical equation.
* Text: "$a^1$: We translate the problem to the equation $\frac{1}{2}(3x-9) = x+37$."
* **Orange Box (Bottom-Left):** Provides definitions for notation used in the diagram.
* Text: "$a^i$: the i-th step of the solution $a$"
* Text: "$a^{i,j}$: the i-th step of the j-th finalized solution"
**2. Center Section (Solution Paths & Outcomes):**
* **Yellow Box (Top-Center):** Represents a single, initial solution attempt.
* Text: "Solution: $a = [a^1, a^2, a^3, ..., a^L]$"
* An arrow points to a white box: "Answer: 85"
* Next to it: "y=0" followed by a red "X" mark, indicating this answer is incorrect.
* **Pink Box (Main Central Area):** Illustrates three distinct, finalized solution paths branching from the initial translation step ($a^1$).
* **Path 1 (Top Row):** $a^{2,1} \rightarrow a^{3,1} \rightarrow ... \rightarrow a^{L1,1}$ leads to "Answer: 83" with "y₁=1" and a green checkmark (✓).
* **Path 2 (Middle Row):** $a^{2,2} \rightarrow a^{3,2} \rightarrow ... \rightarrow a^{L2,2}$ leads to "Answer: 83" with "y₂=1" and a green checkmark (✓).
* **Path 3 (Bottom Row):** $a^{2,3} \rightarrow a^{3,3} \rightarrow ... \rightarrow a^{L3,3}$ leads to "Answer: 87" with "y₃=0" and a red "X" mark.
* **Footer Text (Bottom of Pink Box):** "y: the correctness of the i-th step"
**3. Right Section (Reward Definitions):**
* **Green Boxes (Stacked Vertically on the Right):** Define four different reward functions or labels.
* **Top Box:** "Outcome Reward" with formula: $r = y$
* **Second Box:** "Hard-label" with formula: $r_i = \max_i y_i$
* **Third Box:** "Soft-label" with formula: $r_i = \frac{1}{n} \sum_{i=1}^{n} y_i$
* **Bottom Box:** "Entropy-regularized label" with formula: $r_i = \frac{1}{\eta} \ln \mathbb{E}_{a^{-i} \sim \pi_0} e^{\eta y(a, x)}$
### Detailed Analysis
The diagram details a specific instance of problem-solving:
1. **Problem:** Solve for $x$ in "Half the value of $3x-9$ is $x+37$."
2. **Golden Answer:** The ground truth is 83.
3. **Process Flow:**
* The problem is first translated into the equation $\frac{1}{2}(3x-9) = x+37$ (Step $a^1$).
* From this single starting point, multiple complete solution paths are generated (represented by the sequences in the pink box).
* Each path consists of a series of steps ($a^{i,j}$) leading to a final numerical answer.
* The correctness (`y`) of each final answer is evaluated against the golden answer (83). Answers of 83 are marked correct (`y=1`), while answers of 85 and 87 are marked incorrect (`y=0`).
4. **Reward Calculation:** The right-hand column shows different mathematical formulations for calculating a reward signal (`r_i`) based on the correctness outcomes (`y`). These range from simple outcome-based rewards to more complex entropy-regularized formulations.
### Key Observations
* **Multiple Correct Paths:** Two distinct solution paths (Path 1 and Path 2) both arrive at the correct answer (83), suggesting there may be multiple valid sequences of reasoning steps.
* **Incorrect Paths:** One path (Path 3) and the initial single-path attempt lead to incorrect answers (87 and 85, respectively).
* **Notation:** The diagram introduces specific notation ($a^i$, $a^{i,j}$) to distinguish between steps in a generic solution and steps within specific, finalized solution attempts.
* **Spatial Layout:** The legend/reward definitions are placed on the far right, separate from the process flow. The core process flows left-to-right from problem to solutions, with the branching into multiple paths occurring in the central pink region.
### Interpretation
This diagram conceptualizes a framework for **training or evaluating an AI model on multi-step reasoning tasks**. The core idea is that for a given problem, there isn't just one "correct" solution path, but potentially several. The system generates multiple candidate solution trajectories.
The different reward functions on the right represent various strategies for providing feedback to the model:
* **Outcome Reward:** Only cares about the final answer's correctness.
* **Hard-label:** Takes the best (maximum) correctness score across steps or paths.
* **Soft-label:** Averages correctness, possibly across steps or paths.
* **Entropy-regularized label:** A more sophisticated reward that incorporates exploration (via entropy) into the learning process, common in reinforcement learning to encourage diverse solution strategies.
The presence of both correct and incorrect paths highlights the challenge of credit assignment—determining which specific steps in a long reasoning chain led to a correct or incorrect outcome. This framework appears designed to address that by evaluating entire paths and using different reward signals to guide learning. The "Golden Answer" serves as the ground truth for supervision.