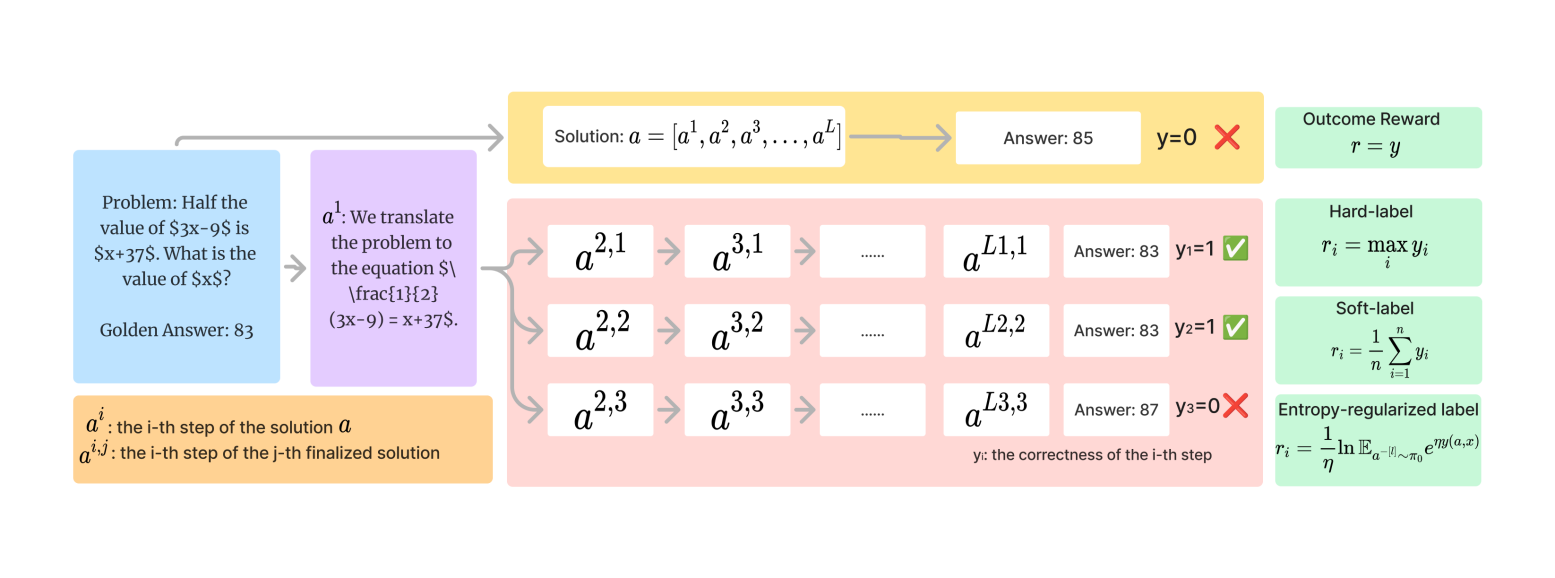
## Flowchart: Problem-Solving Process with Evaluation Mechanisms
### Overview
The diagram illustrates a multi-step problem-solving process involving equation translation, solution generation, and evaluation using different reward mechanisms. It includes a mathematical problem, solution steps with answers, and four evaluation methods (outcome reward, hard-label, soft-label, entropy-regularized label).
### Components/Axes
1. **Problem Section** (Blue Box):
- Problem statement: "Half the value of $3x-9$ is $x+37$. What is the value of $x$?"
- Golden Answer: 83
- Translated equation: $(3x-9) = x+37$
2. **Solution Process** (Yellow Box):
- Solution sequence: $a = [a^1, a^2, a^3, ..., a^L]$
- Final Answer: 85 (marked incorrect with red "X" and $y=0$)
3. **Step-by-Step Evaluation** (Pink Box):
- Substeps labeled $a^{i,j}$ (e.g., $a^{2,1}$, $a^{3,2}$)
- Answers: 83, 87 (with correctness indicators $y=1$ or $y=0$)
- Correctness flags: Green checkmarks (✓) for $y=1$, red crosses (✗) for $y=0$
4. **Reward Mechanisms** (Green Boxes):
- **Outcome Reward**: $r = y$ (directly uses final correctness)
- **Hard-label**: $r_i = \max y_i$ (selects maximum correctness)
- **Soft-label**: $r_i = \frac{1}{n} \sum_{i=1}^n y_i$ (averages correctness)
- **Entropy-regularized label**: $r_i = \frac{1}{\eta} \ln \mathbb{E}_{a^{-[i]}\sim\pi_0} e^{\eta y(a,x)}$ (complex probabilistic formula)
### Detailed Analysis
- **Problem Translation**: The word problem is converted to the equation $(3x-9) = x+37$, with the correct solution $x=83$.
- **Solution Generation**: The process generates a sequence of steps $a^1$ to $a^L$, culminating in an incorrect final answer (85 vs. golden answer 83).
- **Step Evaluation**:
- $a^{L1,1}$: Answer 83 ($y=1$ ✓)
- $a^{L2,2}$: Answer 83 ($y=1$ ✓)
- $a^{L3,3}$: Answer 87 ($y=0$ ✗)
- **Reward Calculations**:
- Outcome Reward: $r = 0$ (final answer incorrect)
- Hard-label: $r_i = 1$ (selects $y=1$ from $a^{L1,1}$ or $a^{L2,2}$)
- Soft-label: $r_i = \frac{2}{3}$ (average of $y=1,1,0$)
- Entropy-regularized: Formula depends on distribution of $y$ values and entropy $\eta$
### Key Observations
1. **Final Answer Discrepancy**: The generated solution (85) differs from the golden answer (83), resulting in $y=0$.
2. **Step Correctness**: Two steps ($a^{L1,1}$, $a^{L2,2}$) correctly identify the golden answer (83), while one step ($a^{L3,3}$) produces an incorrect answer (87).
3. **Reward Divergence**: Different evaluation methods yield varying rewards despite identical step correctness patterns:
- Outcome Reward: 0 (punishes final error)
- Hard-label: 1 (rewards best step)
- Soft-label: ~0.67 (moderate reward)
- Entropy-regularized: Complex reward balancing exploration/exploitation
### Interpretation
The diagram demonstrates how different evaluation strategies impact learning outcomes:
- **Outcome Reward** focuses solely on final correctness, ignoring intermediate steps.
- **Hard-label** prioritizes the most correct step, potentially overlooking partial correctness.
- **Soft-label** provides a balanced view by averaging step correctness.
- **Entropy-regularized Label** introduces uncertainty awareness, encouraging exploration of diverse solutions.
The presence of multiple correct steps ($a^{L1,1}$, $a^{L2,2}$) suggests the model has partial understanding, but the final answer error highlights challenges in maintaining consistency. The entropy-regularized approach may help mitigate this by valuing exploratory steps that contribute to long-term learning, even if individually imperfect.