## Heatmap Comparison: BLEU Score vs. Exact Match by Scenario and Transformation
### Overview
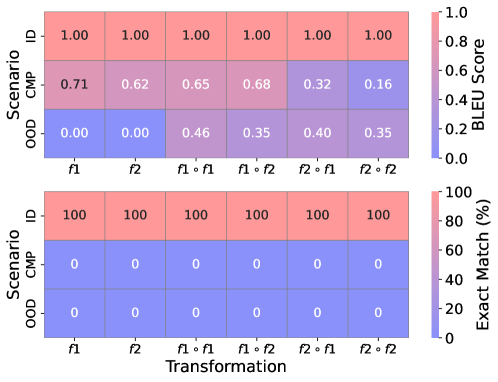
The image displays two vertically stacked heatmaps comparing model performance across three scenarios (ID, CMP, OOD) and six transformations (f1, f2, f1∘f1, f1∘f2, f2∘f1, f2∘f2). The top heatmap visualizes BLEU Scores (0.0 to 1.0 scale), and the bottom heatmap visualizes Exact Match percentages (0% to 100% scale). The color intensity represents the score magnitude, with a corresponding color bar to the right of each chart.
### Components/Axes
* **Y-Axis (Both Charts):** Labeled "Scenario". Categories from top to bottom: `ID`, `CMP`, `OOD`.
* **X-Axis (Both Charts):** Labeled "Transformation". Categories from left to right: `f1`, `f2`, `f1∘f1`, `f1∘f2`, `f2∘f1`, `f2∘f2`.
* **Color Bar (Top Chart):** Labeled "BLEU Score". Scale ranges from 0.0 (blue) to 1.0 (red/pink).
* **Color Bar (Bottom Chart):** Labeled "Exact Match (%)". Scale ranges from 0 (blue) to 100 (red/pink).
### Detailed Analysis
**Top Heatmap: BLEU Score**
* **ID Scenario (Top Row):** All cells show a perfect score of `1.00`. The row is uniformly colored in the darkest red/pink.
* **CMP Scenario (Middle Row):** Scores are moderate to low, ranging from `0.16` to `0.71`. The trend shows a general decrease from left to right. The highest score (`0.71`) is for transformation `f1`. The lowest score (`0.16`) is for transformation `f2∘f2`.
* **OOD Scenario (Bottom Row):** Scores are low, ranging from `0.00` to `0.46`. The first two transformations (`f1`, `f2`) score `0.00`. The highest score (`0.46`) is for transformation `f1∘f1`. The row is predominantly blue, indicating low scores.
**Bottom Heatmap: Exact Match (%)**
* **ID Scenario (Top Row):** All cells show a perfect score of `100`. The row is uniformly colored in the darkest red/pink.
* **CMP Scenario (Middle Row):** All cells show a score of `0`. The entire row is uniformly colored in the darkest blue.
* **OOD Scenario (Bottom Row):** All cells show a score of `0`. The entire row is uniformly colored in the darkest blue.
### Key Observations
1. **Perfect In-Distribution Performance:** The `ID` scenario achieves perfect scores (BLEU=1.00, Exact Match=100%) across all six transformations, indicating flawless performance on in-distribution data.
2. **Complete Exact Match Failure:** Both the `CMP` (Compositional) and `OOD` (Out-of-Distribution) scenarios score `0%` on the Exact Match metric for every transformation, indicating a total failure to generate the exact target output.
3. **Partial Success in BLEU for CMP:** While failing on Exact Match, the `CMP` scenario shows non-zero BLEU scores, suggesting the model generates outputs that are partially similar to the reference (e.g., sharing some words or phrases). Performance degrades for more complex transformations (`f2∘f2`).
4. **Poor OOD Generalization:** The `OOD` scenario shows very low BLEU scores (≤0.46) and zero Exact Match, indicating the model generalizes poorly to completely unseen data distributions.
5. **Transformation Complexity Impact:** For the `CMP` scenario's BLEU scores, simpler transformations (`f1`, `f2`) yield higher scores than their compositions (`f1∘f1`, `f2∘f2`), suggesting performance degrades with increased compositional complexity.
### Interpretation
This data strongly suggests a model that has memorized or perfectly fits its training distribution (`ID` scenario) but lacks robust compositional reasoning and generalization capabilities.
* The **discrepancy between BLEU and Exact Match in the CMP scenario** is critical. It indicates the model can produce *somewhat relevant* language (hence non-zero BLEU) but fails to construct the *precisely correct* sequence of operations or tokens required for an exact match. This points to a weakness in systematic, rule-based reasoning.
* The **complete failure on OOD data** confirms the model's knowledge is not abstracted into generalizable principles. It cannot apply learned patterns to novel contexts.
* The **declining BLEU trend in CMP** for more complex transformations (`f2∘f2` being the lowest) suggests the model's partial compositional ability breaks down as the number of operations or their complexity increases.
In essence, the model exhibits "brittle expertise": it performs perfectly on familiar data but fails fundamentally when required to reason compositionally or generalize to new situations. The heatmap visualizes the stark boundary between its memorized performance and its lack of robust, abstract understanding.