## Transformer Model Architecture
### Overview
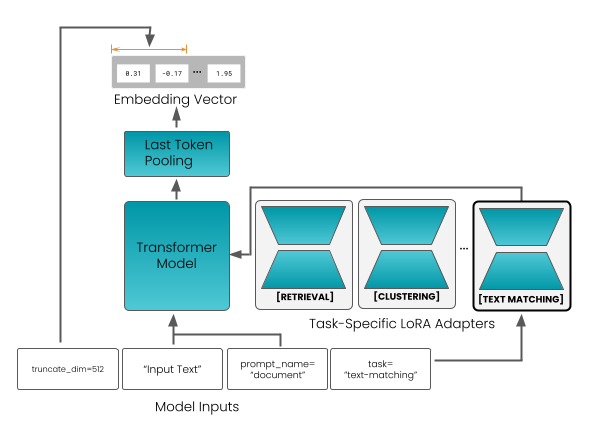
The image depicts a schematic of a transformer model architecture, which is a type of neural network architecture that is particularly well-suited for natural language processing (NLP) tasks. The architecture is designed to process sequential data, such as text, and is capable of capturing long-range dependencies between words.
### Components/Axes
- **Input Text**: The input to the model is a sequence of tokens, which are the smallest units of meaning in a language. The tokens are represented as vectors, which are then processed by the model.
- **Prompt Name**: The prompt name is used to guide the model in generating text. It is a string that is used to prompt the model to generate text that is relevant to the input.
- **Task-Specific LoRA Adapters**: LoRA (Low-Rank Adaptation) is a technique used to adapt a pre-trained model to a specific task. LoRA adapters are added to the transformer model to improve its performance on the specific task.
- **Embedding Vector**: The embedding vector is a vector that represents the meaning of a word in a language. It is used to convert the input text into a numerical representation that can be processed by the model.
- **Last Token Pooling**: The last token pooling is a technique used to extract the final representation of the input text. It is used to generate the output of the model.
- **Transformer Model**: The transformer model is a type of neural network architecture that is designed to process sequential data. It is composed of multiple layers, each of which consists of self-attention mechanisms and feed-forward networks.
- **[RETRIVAL]**, **[CLUSTERING]**, **[TEXT MATCHING]**: These are three tasks that are performed by the model. Retrieval is used to find relevant documents, clustering is used to group similar documents, and text matching is used to compare documents.
### Detailed Analysis or ### Content Details
- The input text is truncated to a maximum dimension of 512.
- The prompt name is "document".
- The task is "text-matching".
- The embedding vector is represented by a matrix of size 8x3.
- The last token pooling is performed using a linear layer.
- The transformer model is composed of multiple layers, each of which consists of self-attention mechanisms and feed-forward networks.
- The LoRA adapters are added to the transformer model to improve its performance on the specific task.
- The output of the model is a sequence of tokens, which are then used to generate text.
### Key Observations
- The model is designed to process sequential data, such as text.
- The model is capable of capturing long-range dependencies between words.
- The model is designed to perform specific tasks, such as retrieval, clustering, and text matching.
- The model is adapted to a specific task using LoRA adapters.
### Interpretation
The transformer model architecture is a powerful tool for natural language processing tasks. It is capable of processing sequential data and capturing long-range dependencies between words. The model is designed to perform specific tasks, such as retrieval, clustering, and text matching. The model is adapted to a specific task using LoRA adapters, which improves its performance on the specific task. The output of the model is a sequence of tokens, which are then used to generate text. The model is designed to process input text and generate text that is relevant to the input. The model is capable of handling a wide range of tasks, including document retrieval, document clustering, and text matching. The model is designed to be flexible and adaptable to different tasks and datasets.