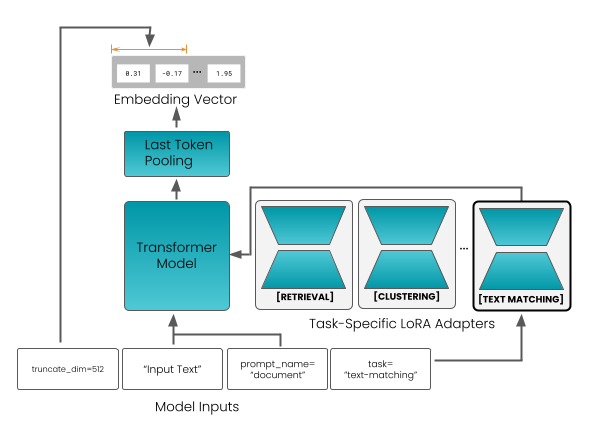
## Diagram: Task-Specific LORA Adapters
### Overview
The image is a diagram illustrating a process flow involving a Transformer Model and Task-Specific LORA Adapters. It shows how input text is processed through the model, adapted for different tasks like retrieval, clustering, and text matching, and ultimately converted into an embedding vector.
### Components/Axes
* **Model Inputs:** Located at the bottom of the diagram.
* `truncate_dim=512`
* `"Input Text"`
* `prompt_name = "document"`
* `task = "text-matching"`
* **Transformer Model:** A teal-colored rectangle in the center of the diagram.
* **Task-Specific LORA Adapters:** A set of three modules enclosed in a rounded rectangle, labeled as "Task-Specific LORA Adapters".
* `[RETRIEVAL]`
* `[CLUSTERING]`
* `[TEXT MATCHING]` (Highlighted with a thicker border)
* **Last Token Pooling:** A teal-colored rectangle above the Transformer Model.
* **Embedding Vector:** A gray rectangle at the top of the diagram. It contains example values:
* `8.31`
* `-0.17`
* `...` (ellipsis indicating more values)
* `1.95`
### Detailed Analysis
1. **Model Inputs:** The diagram starts with "Model Inputs" at the bottom. These inputs include:
* `truncate_dim=512`: Indicates a truncation dimension of 512.
* `"Input Text"`: Represents the input text being fed into the model.
* `prompt_name = "document"`: Specifies the prompt name as "document".
* `task = "text-matching"`: Indicates the task is "text-matching".
2. **Transformer Model:** The "Input Text" is fed into the "Transformer Model".
3. **Task-Specific LORA Adapters:** The output of the "Transformer Model" is then processed by the "Task-Specific LORA Adapters". These adapters include:
* `[RETRIEVAL]`
* `[CLUSTERING]`
* `[TEXT MATCHING]`
4. **Last Token Pooling:** The output from the "Transformer Model" goes through "Last Token Pooling".
5. **Embedding Vector:** Finally, the output from "Last Token Pooling" is converted into an "Embedding Vector". The vector contains example values such as 8.31, -0.17, and 1.95.
### Key Observations
* The diagram illustrates a sequential flow from "Model Inputs" to the "Embedding Vector".
* The "Task-Specific LORA Adapters" module suggests that the model can be adapted for different tasks.
* The "TEXT MATCHING" adapter is highlighted, possibly indicating its relevance or current focus.
### Interpretation
The diagram depicts a system where input text is processed through a Transformer Model and then adapted for various tasks using LORA (Low-Rank Adaptation) adapters. The model takes input text, truncates it to a dimension of 512, and uses a "document" prompt. The output is then tailored for tasks like retrieval, clustering, and text matching. The final output is an embedding vector, which is a numerical representation of the input text suitable for machine learning tasks. The highlighting of the "TEXT MATCHING" adapter suggests that this specific task is of particular interest or importance in the context of the diagram. The use of LORA adapters indicates an efficient way to adapt the model for different tasks without retraining the entire model.