\n
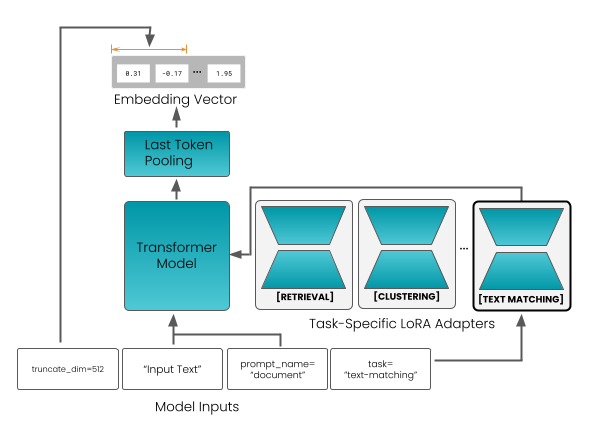
## Diagram: Transformer Model with LoRA Adapters
### Overview
This diagram illustrates the architecture of a Transformer model augmented with Task-Specific LoRA (Low-Rank Adaptation) adapters. The diagram shows the flow of data from model inputs, through the Transformer model, to an embedding vector, and highlights the role of LoRA adapters in tailoring the model for specific tasks.
### Components/Axes
The diagram consists of the following components:
* **Model Inputs:** Labeled "Model Inputs" at the bottom.
* **Transformer Model:** A large teal-colored rectangle labeled "Transformer Model".
* **Task-Specific LoRA Adapters:** Three teal-colored boxes labeled "[RETRIEVAL]", "[CLUSTERING]", and "[TEXT MATCHING]". An ellipsis (...) indicates that there are more adapters.
* **Last Token Pooling:** A rectangular box labeled "Last Token Pooling".
* **Embedding Vector:** A rectangular box labeled "Embedding Vector".
* **Input Text:** A text label within the "Model Inputs" section, reading "Input Text".
* **prompt_name:** A text label within the "Model Inputs" section, reading "prompt_name = document".
* **task:** A text label within the "Model Inputs" section, reading "task = text-matching".
* **truncate_dim:** A text label on the left side, reading "truncate_dim = 512".
* **Embedding Vector Values:** Three values displayed within the "Embedding Vector" box: 8.31, -0.17, and 1.95.
* **Arrow with Length Indicator:** An arrow pointing from the "Embedding Vector" box, with a yellow line indicating a length and associated values.
### Detailed Analysis or Content Details
The diagram shows a data flow starting from "Model Inputs".
1. **Model Inputs:** The inputs consist of "Input Text", a "prompt_name" set to "document", and a "task" set to "text-matching". A "truncate_dim" parameter is set to 512.
2. **Transformer Model:** The "Input Text" and other inputs are fed into the "Transformer Model".
3. **Task-Specific LoRA Adapters:** The output of the "Transformer Model" is then passed through one of several "Task-Specific LoRA Adapters". The diagram shows three adapters: "[RETRIEVAL]", "[CLUSTERING]", and "[TEXT MATCHING]". The ellipsis suggests there are more adapters available.
4. **Last Token Pooling:** The output of the LoRA adapters is then passed to "Last Token Pooling".
5. **Embedding Vector:** The output of "Last Token Pooling" is an "Embedding Vector". The vector contains three values: 8.31, -0.17, and 1.95.
6. **Feedback Loop:** A feedback loop is shown on the left side of the diagram, connecting the "Embedding Vector" back to the "Transformer Model". An arrow indicates a length, with values associated with it.
The Embedding Vector values are:
* 8.31
* -0.17
* 1.95
### Key Observations
The diagram highlights the modularity of the Transformer model through the use of LoRA adapters. This allows the same base Transformer model to be adapted for different tasks without retraining the entire model. The feedback loop suggests a potential iterative refinement process. The values within the embedding vector are numerical representations of the input data after processing.
### Interpretation
The diagram demonstrates a technique for efficiently adapting large language models (LLMs) to specific tasks. LoRA adapters provide a lightweight mechanism for task specialization, reducing the computational cost and data requirements compared to full fine-tuning. The "truncate_dim" parameter suggests that the input text is being truncated to a maximum length of 512 tokens. The embedding vector represents a condensed, numerical representation of the input text, capturing its semantic meaning. The feedback loop could represent a mechanism for refining the embedding based on the task-specific adapter's output. The diagram suggests a system designed for flexibility and efficiency in applying a powerful Transformer model to a variety of downstream tasks.