## Diagram: Transformer Model Architecture with Task-Specific LoRA Adapters
### Overview
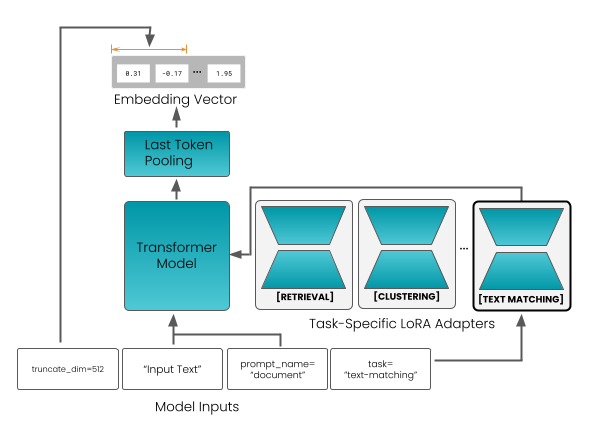
The diagram illustrates a technical architecture for a Transformer-based model integrated with task-specific LoRA (Low-Rank Adaptation) adapters. It shows the flow of data from raw inputs through a Transformer model, followed by task-specific processing via LoRA adapters for applications like retrieval, clustering, and text matching.
### Components/Axes
1. **Model Inputs** (bottom row):
- `truncate_dim=512`
- `Input Text`
- `prompt_name="document"`
- `task="text-matching"`
2. **Core Components** (central flow):
- **Transformer Model**: Processes input text into contextualized representations.
- **Last Token Pooling**: Extracts a single embedding vector from the final token of the Transformer output.
- **Embedding Vector**: A numerical vector (e.g., `[8.31, -0.17, ..., 1.95]`) representing the pooled output.
3. **Task-Specific LoRA Adapters** (right side):
- **Retrieval**
- **Clustering**
- **Text Matching**
4. **Flow Direction**:
- Inputs → Transformer Model → Last Token Pooling → Embedding Vector → Task-Specific Adapters.
### Detailed Analysis
- **Embedding Vector**: Contains numerical values (e.g., `8.31`, `-0.17`, `1.95`), likely representing high-dimensional features extracted from the input text.
- **LoRA Adapters**: Modular components that adapt the base Transformer model for specific tasks without retraining the entire model.
- **Task-Specific Outputs**: Each adapter (Retrieval, Clustering, Text Matching) tailors the Embedding Vector for its respective application.
### Key Observations
1. **Modular Design**: The Transformer Model is reused across tasks, with LoRA adapters enabling efficient task specialization.
2. **Embedding Vector**: Acts as a shared intermediate representation for all downstream tasks.
3. **Numerical Values**: The Embedding Vector includes specific values (e.g., `8.31`, `-0.17`), but their semantic meaning is not explained in the diagram.
### Interpretation
This architecture demonstrates a **parameter-efficient fine-tuning** approach, where a pre-trained Transformer model is adapted to multiple tasks using lightweight LoRA layers. The shared Embedding Vector suggests that the Transformer captures generalizable features, while the adapters specialize these features for specific applications. The numerical values in the Embedding Vector likely encode contextualized text representations, but their exact interpretation (e.g., semantic meaning, magnitude) requires additional context.
**Critical Insight**: The use of LoRA adapters reduces computational overhead compared to full model retraining, making this architecture scalable for diverse NLP tasks.