TECHNICAL ASSET FINGERPRINT
1f10e77e0d7e5c67b2e15d8c
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemini-2.0-flash VERSION 1
RUNTIME: nugit/gemini/gemini-2.0-flash
INTEL_VERIFIED
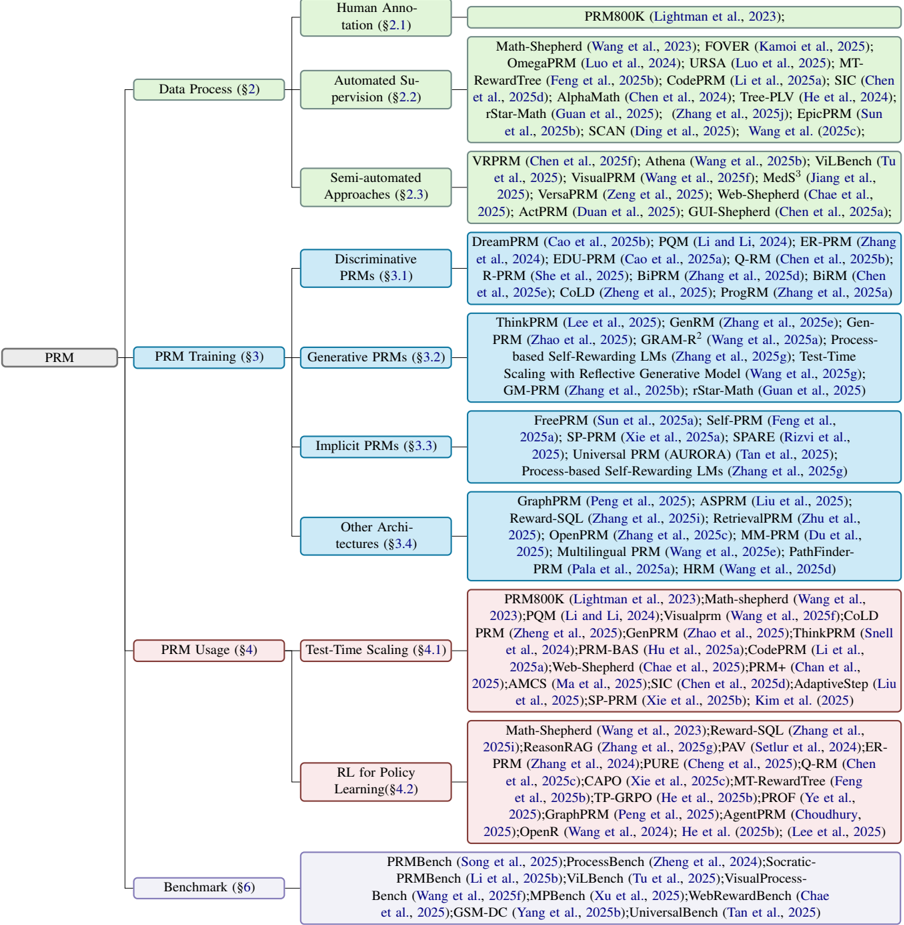
## Flowchart: PRM Taxonomy
### Overview
The image is a flowchart that categorizes different types of PRM (likely standing for "Probabilistic RoadMap") algorithms and related concepts. It branches out from a central "PRM" node into various subcategories like data processing, training, usage, and benchmarking, further detailing specific algorithms and techniques within each category.
### Components/Axes
* **Main Node:** PRM
* **Level 1 Categories:**
* Data Process (§2) - Light Green
* PRM Training (§3) - Blue
* PRM Usage (§4) - Red
* Benchmark (§6) - Purple
* **Level 2 Categories (under Data Process):**
* Human Annotation (§2.1) - Light Green
* Automated Supervision (§2.2) - Light Green
* Semi-automated Approaches (§2.3) - Light Green
* **Level 2 Categories (under PRM Training):**
* Discriminative PRMs (§3.1) - Blue
* Generative PRMs (§3.2) - Blue
* Implicit PRMs (§3.3) - Blue
* Other Architectures (§3.4) - Blue
* **Level 2 Categories (under PRM Usage):**
* Test-Time Scaling (§4.1) - Red
* RL for Policy Learning (§4.2) - Red
### Detailed Analysis or ### Content Details
**1. Data Process (§2) - Light Green**
* Human Annotation (§2.1): No specific algorithms listed.
* Automated Supervision (§2.2): PRM800K (Lightman et al., 2023)
* Semi-automated Approaches (§2.3):
* Math-Shepherd (Wang et al., 2023)
* FOVER (Kamoi et al., 2025)
* OmegaPRM (Luo et al., 2024)
* URSA (Luo et al., 2025)
* MT-RewardTree (Feng et al., 2025b)
* CodePRM (Li et al., 2025a)
* SIC (Chen et al., 2025d)
* AlphaMath (Chen et al., 2024)
* Tree-PLV (He et al., 2024)
* rStar-Math (Guan et al., 2025)
* (Zhang et al., 2025j)
* EpicPRM (Sun et al., 2025b)
* SCAN (Ding et al., 2025)
* Wang et al. (2025c)
**2. PRM Training (§3) - Blue**
* Discriminative PRMs (§3.1):
* VRPRM (Chen et al., 2025f)
* Athena (Wang et al., 2025b)
* ViLBench (Tu et al., 2025)
* VisualPRM (Wang et al., 2025f)
* MedS³ (Jiang et al., 2025)
* VersaPRM (Zeng et al., 2025)
* Web-Shepherd (Chae et al., 2025)
* ActPRM (Duan et al., 2025)
* GUI-Shepherd (Chen et al., 2025a)
* Generative PRMs (§3.2):
* DreamPRM (Cao et al., 2025b)
* PQM (Li and Li, 2024)
* ER-PRM (Zhang et al., 2024)
* EDU-PRM (Cao et al., 2025a)
* Q-RM (Chen et al., 2025b)
* R-PRM (She et al., 2025)
* BiPRM (Zhang et al., 2025d)
* BiRM (Chen et al., 2025e)
* CoLD (Zheng et al., 2025)
* ProgRM (Zhang et al., 2025a)
* Implicit PRMs (§3.3):
* ThinkPRM (Lee et al., 2025)
* GenRM (Zhang et al., 2025e)
* Gen-PRM (Zhao et al., 2025)
* GRAM-R2 (Wang et al., 2025a)
* Process-based Self-Rewarding LMs (Zhang et al., 2025g)
* Test-Time Scaling with Reflective Generative Model (Wang et al., 2025g)
* GM-PRM (Zhang et al., 2025b)
* rStar-Math (Guan et al., 2025)
* Other Architectures (§3.4):
* FreePRM (Sun et al., 2025a)
* Self-PRM (Feng et al., 2025a)
* SP-PRM (Xie et al., 2025a)
* SPARE (Rizvi et al., 2025)
* Universal PRM (AURORA) (Tan et al., 2025)
* Process-based Self-Rewarding LMs (Zhang et al., 2025g)
* GraphPRM (Peng et al., 2025)
* ASPRM (Liu et al., 2025)
* Reward-SQL (Zhang et al., 2025i)
* RetrievalPRM (Zhu et al., 2025)
* OpenPRM (Zhang et al., 2025c)
* MM-PRM (Du et al., 2025)
* Multilingual PRM (Wang et al., 2025e)
* PathFinder-PRM (Pala et al., 2025a)
* HRM (Wang et al., 2025d)
**3. PRM Usage (§4) - Red**
* Test-Time Scaling (§4.1):
* PRM800K (Lightman et al., 2023)
* Math-shepherd (Wang et al., 2023)
* PQM (Li and Li, 2024)
* Visualprm (Wang et al., 2025f)
* CoLD PRM (Zheng et al., 2025)
* GenPRM (Zhao et al., 2025)
* ThinkPRM (Snell et al., 2024)
* PRM-BAS (Hu et al., 2025a)
* CodePRM (Li et al., 2025a)
* Web-Shepherd (Chae et al., 2025)
* PRM+ (Chan et al., 2025)
* AMCS (Ma et al., 2025)
* SIC (Chen et al., 2025d)
* AdaptiveStep (Liu et al., 2025)
* SP-PRM (Xie et al., 2025b)
* Kim et al. (2025)
* RL for Policy Learning (§4.2):
* Math-Shepherd (Wang et al., 2023)
* Reward-SQL (Zhang et al., 2025i)
* ReasonRAG (Zhang et al., 2025g)
* PAV (Setlur et al., 2024)
* ER-PRM (Zhang et al., 2024)
* PURE (Cheng et al., 2025)
* Q-RM (Chen et al., 2025c)
* CAPO (Xie et al., 2025c)
* MT-RewardTree (Feng et al., 2025b)
* TP-GRPO (He et al., 2025b)
* PROF (Ye et al., 2025)
* GraphPRM (Peng et al., 2025)
* AgentPRM (Choudhury, 2025)
* OpenR (Wang et al., 2024)
* He et al. (2025b)
* (Lee et al., 2025)
**4. Benchmark (§6) - Purple**
* PRMBench (Song et al., 2025)
* ProcessBench (Zheng et al., 2024)
* Socratic-PRMBench (Li et al., 2025b)
* ViLBench (Tu et al., 2025)
* Visual Process-Bench (Wang et al., 2025f)
* MPBench (Xu et al., 2025)
* WebRewardBench (Chae et al., 2025)
* GSM-DC (Yang et al., 2025b)
* UniversalBench (Tan et al., 2025)
### Key Observations
* The flowchart provides a hierarchical organization of PRM-related concepts.
* Each category lists specific algorithms or techniques, along with associated publications (authors and year).
* The years listed are mostly in the future (2024, 2025), suggesting this is either a projection or a typo.
* The most granular level lists specific PRM algorithms and associated publications.
### Interpretation
The flowchart serves as a taxonomy or classification system for PRM algorithms and related research. It highlights the different stages of PRM development (data processing, training, usage) and provides a structured overview of the field. The inclusion of specific algorithms and their corresponding publications makes it a valuable resource for researchers and practitioners in the area of probabilistic roadmaps and motion planning. The future dates suggest this is a forward-looking view of the field.
DECODING INTELLIGENCE...
EXPERT: nemotron-free VERSION 1
RUNTIME: free/nvidia/nemotron-nano-12b-v2-vl:free
INTEL_VERIFIED
## Hierarchical Diagram: PRM (Probabilistic Reward Models) Taxonomy
### Overview
The diagram presents a hierarchical taxonomy of Probabilistic Reward Models (PRMs), organized into five main categories: **Human Annotation**, **Data Process**, **PRM Training**, **PRM Usage**, and **Benchmark**. Each category branches into subcategories with specific methods, papers, and years. Color coding distinguishes main categories: green (Human Annotation/Data Process), blue (PRM Training), pink (PRM Usage), and purple (Benchmark).
### Components/Axes
- **Main Categories** (Top-level labels):
- Human Annotation ($2.1)
- Data Process ($2)
- PRM Training ($3)
- PRM Usage ($4)
- Benchmark ($6)
- **Subcategories** (Nested under main categories):
- Automated Supervision ($2.2)
- Semi-automated Approaches ($2.3)
- Discriminative PRMs ($3.1)
- Generative PRMs ($3.2)
- Implicit PRMs ($3.3)
- Other Architectures ($3.4)
- Test-Time Scaling ($4.1)
- RL for Policy Learning ($4.2)
- **Legend**:
- Green: Human Annotation, Data Process
- Blue: PRM Training
- Pink: PRM Usage
- Purple: Benchmark
### Detailed Analysis
#### Human Annotation ($2.1)
- **Methods**:
- PRM800K (Lightman et al., 2023)
- Math-Shepherd (Wang et al., 2023)
- FOVER (Kamoi et al., 2025)
- OmegaPRM (Luo et al., 2024)
- URSA (Luo et al., 2025)
- MT-RewardTree (Feng et al., 2025b)
- CodePRM (Li et al., 2025)
- SIC (Chen et al., 2025)
- AlphaMath (Chen et al., 2024)
- Tree-PLV (He et al., 2024)
- rStarMath (Guan et al., 2025)
- Zeng et al. (2025b)
- SCAN (Ding et al., 2025)
- WANG et al. (2025c)
#### Data Process ($2)
- **Subcategories**:
- **Automated Supervision ($2.2)**:
- PRM800K (Lightman et al., 2023)
- Math-Shepherd (Wang et al., 2023)
- FOVER (Kamoi et al., 2025)
- OmegaPRM (Luo et al., 2024)
- URSA (Luo et al., 2025)
- MT-RewardTree (Feng et al., 2025b)
- CodePRM (Li et al., 2025)
- SIC (Chen et al., 2025)
- AlphaMath (Chen et al., 2024)
- Tree-PLV (He et al., 2024)
- rStarMath (Guan et al., 2025b)
- SCAN (Ding et al., 2025)
- WANG et al. (2025c)
- **Semi-automated Approaches ($2.3)**:
- VPRPM (Chen et al., 2025f)
- Athena (Wang et al., 2025b)
- ViLBench (Tu et al., 2025)
- VisualPRM (Wang et al., 2025f)
- MedS³ (Jiang et al., 2025)
- VersaPRM (Zeng et al., 2025)
- Web-Shepherd (Wang et al., 2025)
- ActPRM (Duan et al., 2025)
- GUI-Shepherd (Chen et al., 2025a)
#### PRM Training ($3)
- **Subcategories**:
- **Discriminative PRMs ($3.1)**:
- DreamPRM (Cao et al., 2025b)
- EDU-PRM (Cao et al., 2025a)
- PQM (Li and Li, 2024)
- ER-PRM (Zhang et al., 2024)
- R-PRM (She et al., 2025)
- BiPRM (Zhang et al., 2025b)
- QRM (Chen et al., 2025b)
- ColD (Zheng et al., 2025)
- ProgRM (Zhang et al., 2025a)
- **Generative PRMs ($3.2)**:
- PRMTPRM (Zhao et al., 2025)
- GRAM-R² (Wang et al., 2025a)
- Process-based Self-Rewarding LMs (Zhang et al., 2025g)
- Test-Time Scaling with Reflective Generative Model (Wang et al., 2025g)
- GM-PRM (Zhang et al., 2025b)
- rStarMath (Guan et al., 2025)
- **Implicit PRMs ($3.3)**:
- FreePRM (Sun et al., 2025a)
- Self-PRM (Feng et al., 2025a)
- SP-PRM (Xie et al., 2025a)
- SPARE (Rizvi et al., 2025)
- Universal PRM (AURORA) (Tan et al., 2025)
- Process-based Self-Rewarding LMs (Zhang et al., 2025g)
- **Other Architectures ($3.4)**:
- GraphPRM (Peng et al., 2025)
- ASPRM (Liu et al., 2025)
- Reward-SQL (Zhang et al., 2025i)
- RetrievalPRM (Zhu et al., 2025)
- OpenPRM (Zhang et al., 2025c)
- MM-PRM (Du et al., 2025)
- Multilingual PRM (HRM et al., 2025e)
- PathFinderPRM (Pala et al., 2025a)
- WRM (Wang et al., 2025)
#### PRM Usage ($4)
- **Subcategories**:
- **Test-Time Scaling ($4.1)**:
- PRM800K (Lightman et al., 2023)
- Math-Shepherd (Wang et al., 2023)
- PQM (Li and Li, 2024)
- Visualpralm (Wang et al., 2025f)
- ThinkPRM (Zeng et al., 2025)
- PRM-BAS (Hu et al., 2025a)
- CodePRM (Li et al., 2025)
- Web-Shepherd (Chae et al., 2025)
- PRM+ (Chan et al., 2025)
- AMCMS (Ma et al., 2025)
- SIC (Chen et al., 2025d)
- AdaptiveStep (Liu et al., 2025)
- SP-PRM (Xie et al., 2025b)
- Kim et al. (2025)
- **RL for Policy Learning ($4.2)**:
- PRMBench (Song et al., 2025)
- ProcessBench (Zheng et al., 2024)
- SocraticBench (Li et al., 2025b)
- ViLBench (Tu et al., 2025)
- VisualProcessBench (Li et al., 2025b)
- ViLBench (Tu et al., 2025)
- WebRewardBench (Chae et al., 2025)
- ReasonRAG (Zhang et al., 2025)
- P-SQL (Zhu et al., 2024)
- ER-PRM (Zhang et al., 2024)
- PURE (Cheng et al., 2025)
- QRM (Chen et al., 2025c)
- CAPO (Xie et al., 2025c)
- MT-RewardTree (Feng et al., 2025b)
- TG-GRPO (He et al., 2025b)
- PROF (Ye et al., 2025)
- GraphPRM (Peng et al., 2025)
- AgentPRM (Choudhury, 2025)
- OpenR (Wang et al., 2024)
- He et al. (2025b)
- Lee et al. (2025)
#### Benchmark ($6)
- **Methods**:
- PRMBench (Song et al., 2025)
- PRMBench (Li et al., 2025b)
- ViLBench (Tu et al., 2025)
- VisualProcessBench (Li et al., 2025b)
- WebRewardBench (Chae et al., 2025)
- GSM-DC (Yang et al., 2025b)
- UniversalBench (Tan et al., 2025)
### Key Observations
1. **Temporal Trends**: Most methods are from 2024–2025, indicating rapid development in PRM research.
2. **Method Diversity**: Subcategories like "Generative PRMs" and "Implicit PRMs" show significant innovation.
3. **Color Consistency**: Legend colors align with categories (e.g., blue for PRM Training).
4. **Overlap**: Some methods appear in multiple subcategories (e.g., PRM800K in both Human Annotation and Data Process).
### Interpretation
The diagram illustrates the rapid evolution of PRMs, with a focus on training methodologies (e.g., generative and implicit models) and practical applications (e.g., test-time scaling). The hierarchical structure highlights interdisciplinary approaches, integrating reinforcement learning (RL) and multilingual capabilities. The dominance of 2024–2025 publications suggests a surge in research activity, possibly driven by advancements in large language models (LLMs). The inclusion of benchmarks like PRMBench and ViLBench underscores the need for standardized evaluation frameworks.
DECODING INTELLIGENCE...