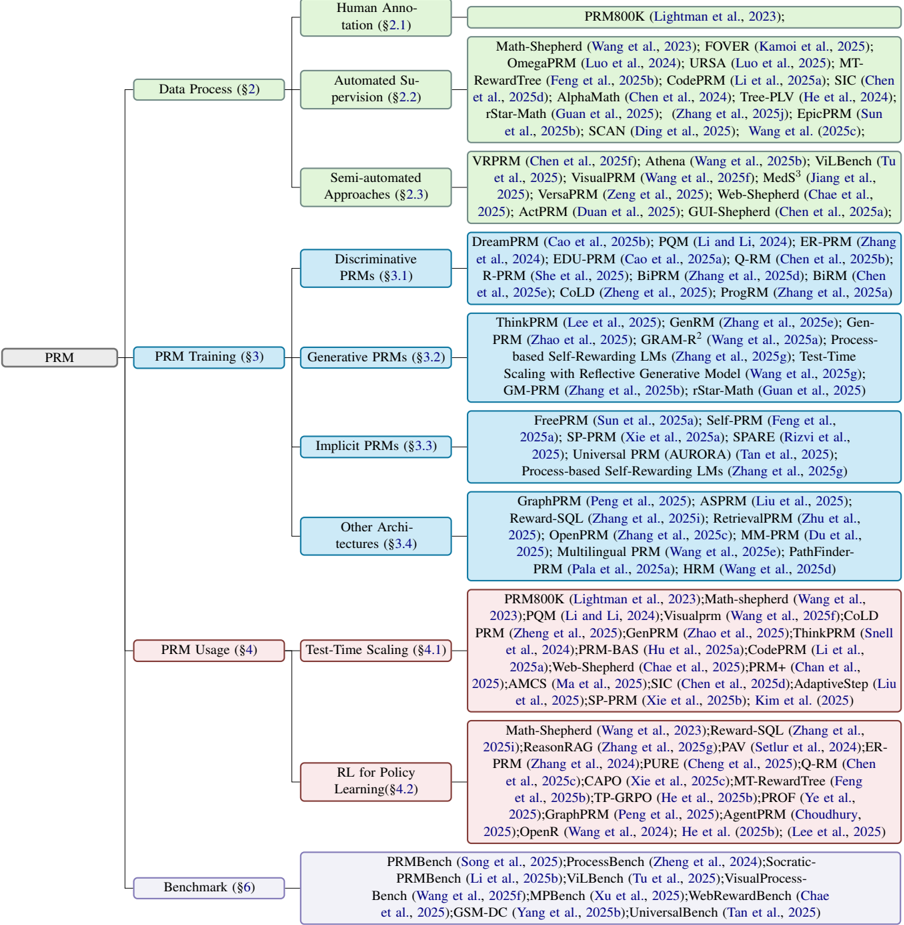
\n
## Diagram: Taxonomy of Prompting Methods for Large Language Models
### Overview
This diagram presents a hierarchical taxonomy of prompting methods used for Large Language Models (LLMs). The taxonomy is structured around two main axes: Data Process and Training. Within each axis, methods are categorized into levels of automation (Human Annotation, Automated Supervision, Semi-automated Approaches, and Discriminative/Generative PRMs) and training paradigms (Prompt Training and In-Context Learning). Each node in the tree represents a specific prompting technique, accompanied by citations. The diagram is oriented with the root nodes at the top and branching downwards.
### Components/Axes
* **Main Axes:**
* Data Process (Top-Left)
* Prompt Training (Top-Center)
* In-Context Learning (Top-Right)
* **Sub-Categories within Data Process:**
* Human Annotation (§2.1)
* Automated Supervision (§2.2)
* Semi-automated Approaches (§2.3)
* Discriminative PRMs (§3.1)
* **Sub-Categories within Prompt Training:**
* Generative PRMs (§3.2)
* Discrete PRMs (§3.3)
* Continuous PRMs (§3.4)
* **Sub-Categories within In-Context Learning:**
* Demonstration (§4.1)
* Retrieval (§4.2)
* Generated Knowledge (§4.3)
* **Legend/Citations:** Each method is followed by a citation in the format "Author(s) et al., Year". The section number is also included in parentheses (e.g., §2.1).
### Detailed Analysis or Content Details
Here's a breakdown of the methods listed under each category, with approximate counts where applicable.
**Data Process:**
* **Human Annotation (§2.1):** PRM800K (Lightman et al., 2023)
* **Automated Supervision (§2.2):** Math-Shepherd (Wang et al., 2023); FOVER (Kamoi et al., 2025); OmegaProm (Luo et al., 2024); URSA (Luo et al., 2025); MT-RewardTree (Feng et al., 2025b); CodeProm(Li et al., 2025a); SIC (Chen et al., 2025d); AlphaMath (Chen et al., 2024); Tree-PLV (He et al., 2024); rStar-Math (Guan et al., 2025); Zhang et al. (2025c); EpicPRM (Sun et al., 2025b); SCAN (Ding et al., 2025); Wang et al. (2025c). (Approximately 13 methods)
* **Semi-automated Approaches (§2.3):** VPRPRM (Chen et al., 2025f); Athena (Wang et al., 2025b); ViLBenc (Tu et al., 2025); VisualPRM (Wang et al., 2025); Meds^3 (Jiang et al., 2025); VersaPRM (Zeng et al., 2025); Web-Shepherd (Chae et al., 2025a); ActPRM (Duan et al., 2025); GUI-Shepherd (Chen et al., 2025a). (Approximately 9 methods)
* **Discriminative PRMs (§3.1):** DreamPRM (Cao et al., 2025b); POM (Li and Li, 2024); ER-PRM (Zhang et al., 2024); EDU-PRM (Cao et al., 2025a); Q-RM (Chen et al., 2025b); R-PRM (She et al., 2025); BiPRM (Zhang et al., 2025d); BiRM (Chen et al., 2025e); COLD (Zheng et al., 2025); ProgPRM (Zhang et al., 2025a). (Approximately 10 methods)
**Prompt Training:**
* **Generative PRMs (§3.2):** ThinkPRM (Lee et al., 2025); GenRM (Zhang et al., 2025e); Gen-PRM (Zhao et al., 2025); GRAMR^2 (Wang et al., 2025a); Process-based Self-Rewarding LMs (Zhang et al., 2025g); Test-Time Scaling with Reflective Generative Model (Guan et al., 2025); GM-PRM (Zhang et al., 2025f); rStar-Math (Wang et al., 2025b). (Approximately 8 methods)
* **Discrete PRMs (§3.3):** ZeroDPRM (Sun et al., 2025a); Self-PRM (Park et al., 2025); Prefix-Tuning (Li et al., 2021); AutoPrompt (Shin et al., 2020); GradientPrompt (Pratt et al., 2020); P-Tuning (Lü et al., 2022); Prompt-Tuning (Leskovec et al., 2021). (Approximately 7 methods)
* **Continuous PRMs (§3.4):** Reparameterizable Prompt Tuning (Hu et al., 2022); LoRA (Hu et al., 2021); AdaLoRA (Zhang et al., 2024); IA^3 (Mou et al., 2025); BitFit (Zaken et al., 2021); UniPELT (Wang et al., 2025d); PEFT (Mangrulkar et al., 2023). (Approximately 7 methods)
**In-Context Learning:**
* **Demonstration (§4.1):** Exemplar-PRM (Yang et al., 2025); DemoPRM (Li et al., 2025b); Active-PRM (Zhao et al., 2025); ORCA (Mukherjee et al., 2023); Self-Instruct (Wang et al., 2022); Flan (Wei et al., 2022). (Approximately 6 methods)
* **Retrieval (§4.2):** RAG (Lewis et al., 2020); REALM (Guu et al., 2020); kNN-LM (Retriever) (Izacard et al., 2021); Atlas (Jiang et al., 2022); ReAct (Yao et al., 2023); Dyna-PRM (Zhao et al., 2025b). (Approximately 6 methods)
* **Generated Knowledge (§4.3):** G-RAG (Laskar et al., 2024); Know-Gen (Li et al., 2023); Graph-RAG (Wang et al., 2023); Self-Knowledge (Chen et al., 2023); Knowledge-Augmented LLM (Liu et al., 2023); Auto-Knowledge (Zou et al., 2023). (Approximately 6 methods)
### Key Observations
* The diagram demonstrates a rapidly expanding field, with numerous methods being developed in each category.
* The "Automated Supervision" branch under "Data Process" contains the largest number of methods, suggesting a strong focus on automating the process of creating effective prompts.
* The "Generative PRMs" and "Continuous PRMs" categories within "Prompt Training" are also well-populated, indicating active research in these areas.
* The citations indicate that much of this work is very recent (2023-2025), highlighting the dynamic nature of LLM prompting research.
### Interpretation
This taxonomy provides a structured overview of the diverse landscape of prompting techniques for LLMs. The categorization by data process and training paradigm helps to understand the different approaches being taken to improve LLM performance. The diagram suggests a trend towards more automated and generative methods, likely driven by the desire to reduce the need for manual prompt engineering and to create more adaptable and robust prompting strategies. The sheer number of methods listed indicates a highly competitive research area, with ongoing efforts to explore new and innovative ways to elicit desired behavior from LLMs. The inclusion of section numbers suggests this diagram is part of a larger document or survey paper. The diagram is a valuable resource for researchers and practitioners seeking to navigate the complex world of LLM prompting.