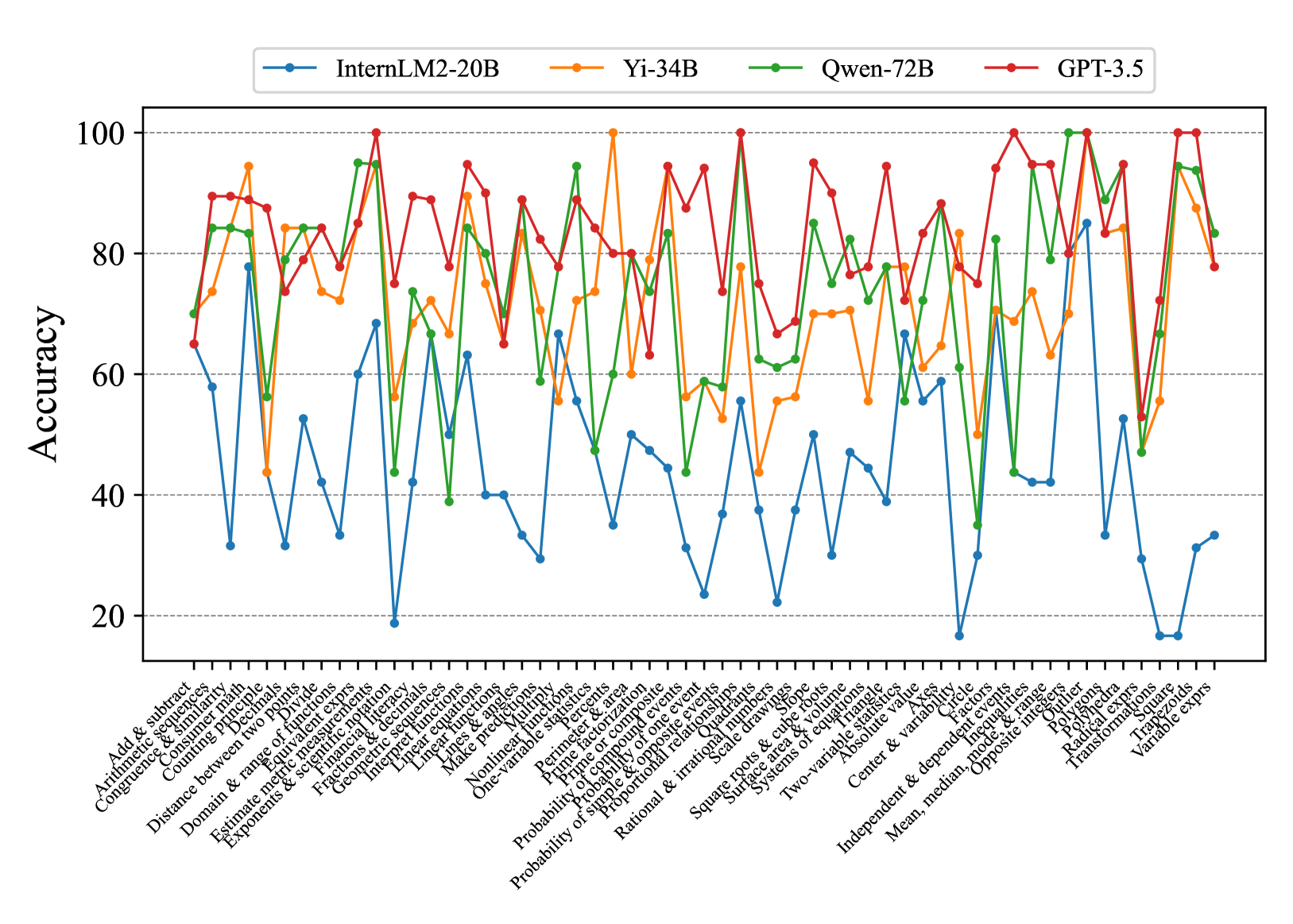
\n
## Line Chart: Model Accuracy on Math Problems
### Overview
This line chart compares the accuracy of four large language models – InternLM2-20B, Yi-34B, Qwen-72B, and GPT-3.5 – on a series of 33 math problems. The x-axis represents the math problem type, and the y-axis represents the accuracy score, ranging from 0 to 100. The chart displays the performance of each model as a line, allowing for a visual comparison of their strengths and weaknesses across different problem types.
### Components/Axes
* **X-axis:** Math Problem Type (Categorical). The problems are listed as: "Add & subtract", "Arithmetic & significant", "Congruence & similar", "Comparing decimals", "Domain & range", "Distance between two points", "Estimate & measure", "Exponents & radicals", "Experience & decimals", "Factorize & expand", "Integers & decimals", "Linear functions", "Make predictions", "Nonlinear functions", "One-variable equations", "Parallel & perpendicular", "Perimeter & area", "Prime & composite", "Probability of one event", "Probability of simple events", "Probability of two events", "Rational & irrational", "Solve equations", "Surface area & volume", "Systems of equations", "Two-variable equations", "Absolute value", "Center & variation", "Independent & dependent variable", "Mean, median, mode", "Opposite & inverse", "Radial measure", "Transformations", "Variable expressions".
* **Y-axis:** Accuracy (Numerical, 0-100).
* **Legend:** Located at the top-left of the chart, identifying each line by model name and color:
* InternLM2-20B (Yellow)
* Yi-34B (Orange)
* Qwen-72B (Green)
* GPT-3.5 (Red)
### Detailed Analysis
The chart shows the accuracy of each model for each math problem. I will analyze each model's performance, noting trends and approximate values.
* **InternLM2-20B (Yellow):** Starts at approximately 80% accuracy for "Add & subtract", dips to around 20% for "Congruence & similar", rises to around 60% for "Linear functions", then fluctuates between 20-40% for most subsequent problems, ending at approximately 25% for "Variable expressions". The line is generally volatile.
* **Yi-34B (Orange):** Begins at approximately 85% for "Add & subtract", drops to around 30% for "Congruence & similar", peaks at around 95% for "Factorize & expand", then generally declines, fluctuating between 30-70% for the remaining problems, finishing at approximately 40% for "Variable expressions". This line shows more pronounced peaks and valleys.
* **Qwen-72B (Green):** Starts at approximately 75% for "Add & subtract", dips to around 20% for "Congruence & similar", rises to around 80% for "Linear functions", then generally declines, fluctuating between 20-60% for the remaining problems, ending at approximately 30% for "Variable expressions". This line is relatively stable compared to the others.
* **GPT-3.5 (Red):** Starts at approximately 90% for "Add & subtract", dips to around 60% for "Congruence & similar", remains relatively high (70-100%) for many problems, including "Factorize & expand", "Linear functions", and "Solve equations", then declines towards the end, finishing at approximately 65% for "Variable expressions". This line consistently demonstrates the highest accuracy across most problem types.
### Key Observations
* GPT-3.5 consistently outperforms the other models across most problem types, maintaining a higher accuracy level.
* All models struggle with "Congruence & similar" problems, exhibiting the lowest accuracy scores for this category.
* Yi-34B shows a significant peak in accuracy for "Factorize & expand", exceeding the performance of other models on this specific problem.
* InternLM2-20B exhibits the most volatile performance, with large fluctuations in accuracy across different problem types.
* The accuracy of all models generally declines towards the end of the problem sequence, suggesting increasing difficulty or a shift in problem characteristics.
### Interpretation
The data suggests that GPT-3.5 is the most proficient model in solving the presented range of math problems. The consistent high accuracy indicates a strong understanding of mathematical concepts and problem-solving abilities. The shared weakness across all models on "Congruence & similar" problems suggests this area requires further improvement in language model training. The peak performance of Yi-34B on "Factorize & expand" could be attributed to specific training data or architectural strengths related to algebraic manipulation. The declining accuracy towards the end of the sequence might indicate that the later problems are more complex or require different mathematical skills than the earlier ones. The volatility of InternLM2-20B suggests it may be more sensitive to the specific phrasing or structure of the problems. Overall, the chart provides valuable insights into the strengths and weaknesses of different language models in the domain of mathematical reasoning.