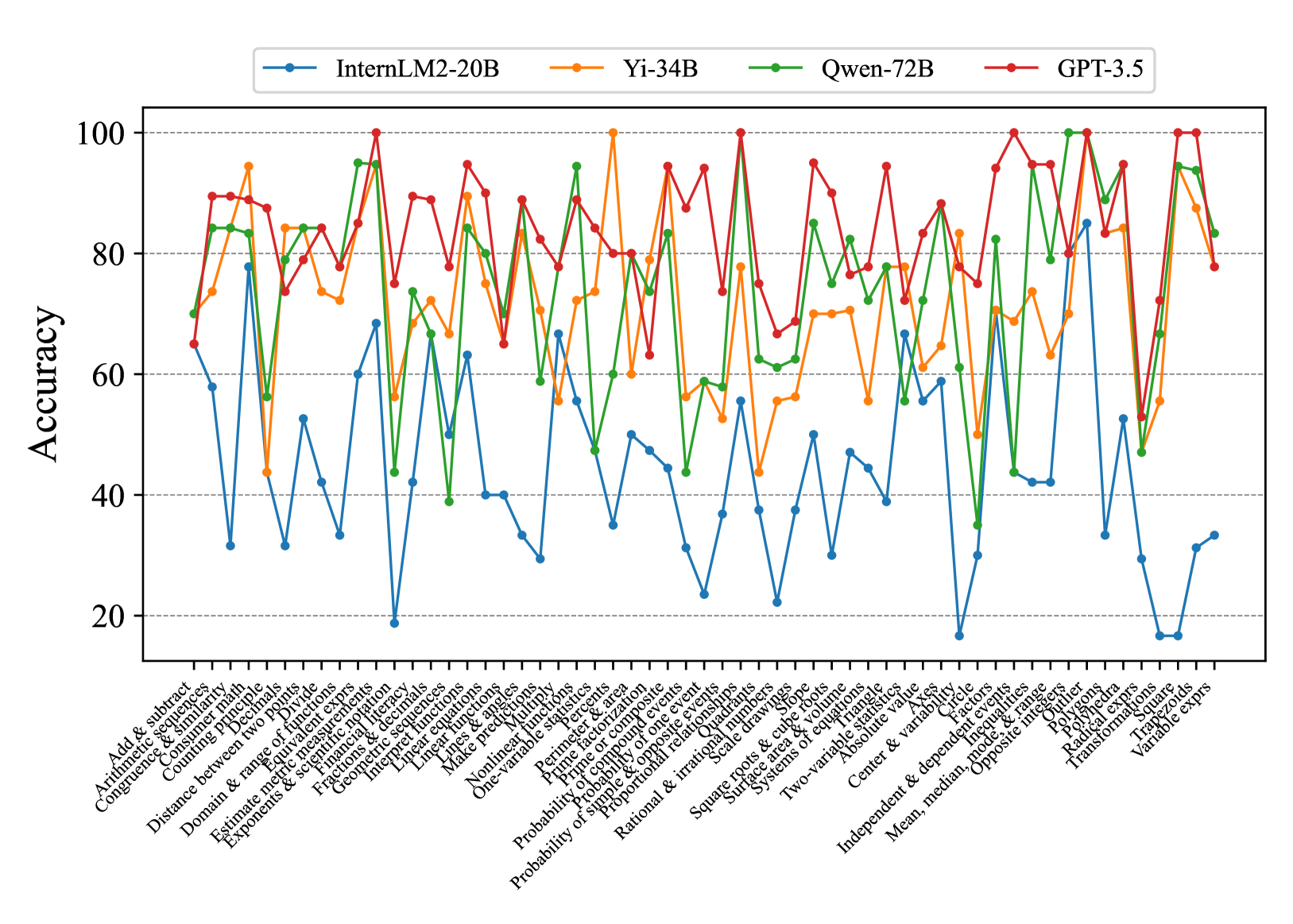
## Line Graph: Model Accuracy Comparison Across Math Tasks
### Overview
The image is a multi-line graph comparing the accuracy of four AI models (InternLM2-20B, Yi-34B, Qwen-72B, GPT-3.5) across 30+ math-related tasks. Accuracy is measured on a 0-100% scale, with tasks spanning arithmetic, algebra, geometry, and advanced mathematics.
### Components/Axes
- **X-axis**: Math tasks (e.g., "Add & subtract," "Arithmetic sequences," "Exponents & scientific notation," "Variable exprs")
- **Y-axis**: Accuracy percentage (0-100%, increments of 20)
- **Legend**: Top-right corner, color-coded:
- Blue: InternLM2-20B
- Orange: Yi-34B
- Green: Qwen-72B
- Red: GPT-3.5
### Detailed Analysis
1. **GPT-3.5 (Red Line)**:
- Consistently highest accuracy (75-100% range)
- Peaks at 100% for tasks like "Prime factorization" and "Polynomials"
- Slight dips below 90% for "Probability & variability" and "Radical expressions"
2. **Qwen-72B (Green Line)**:
- Second-highest performance (60-95% range)
- Matches GPT-3.5 in "Geometry & range" and "Nonlinear functions"
- Struggles with "Probability of simple events" (60%) and "Surface area & volume" (70%)
3. **Yi-34B (Orange Line)**:
- Third performer (50-85% range)
- Excels in "Exponents & scientific notation" (90%) and "Linear equations" (85%)
- Weaknesses: "Probability & variability" (50%) and "Radical expressions" (65%)
4. **InternLM2-20B (Blue Line)**:
- Lowest performance (20-60% range)
- Strong in "Add & subtract" (60%) and "Arithmetic sequences" (70%)
- Severe drops in "Probability & variability" (15%) and "Variable exprs" (30%)
### Key Observations
- **GPT-3.5 dominance**: Outperforms all models in 22/30 tasks, with 100% accuracy in 5 tasks
- **Size vs. performance**: Larger models (Qwen-72B, Yi-34B) generally outperform smaller ones, but Yi-34B (34B params) underperforms Qwen-72B (72B params) in 14 tasks
- **Task complexity correlation**: Accuracy drops for all models in advanced topics (e.g., "Polynomials" vs. "Add & subtract")
- **Consistency**: GPT-3.5 shows least variance (SD ~5%), while InternLM2-20B has highest volatility (SD ~25%)
### Interpretation
The graph reveals GPT-3.5's superior mathematical reasoning capabilities, likely due to its specialized training or architecture. Qwen-72B and Yi-34B demonstrate comparable performance despite size differences, suggesting parameter count isn't the sole determinant of math proficiency. InternLM2-20B's significant underperformance in complex tasks highlights potential limitations in handling abstract mathematical concepts. The data suggests model architecture and training data quality may be more critical than size alone for mathematical reasoning tasks.