\n
## Diagram: Image Captioning Architecture
### Overview
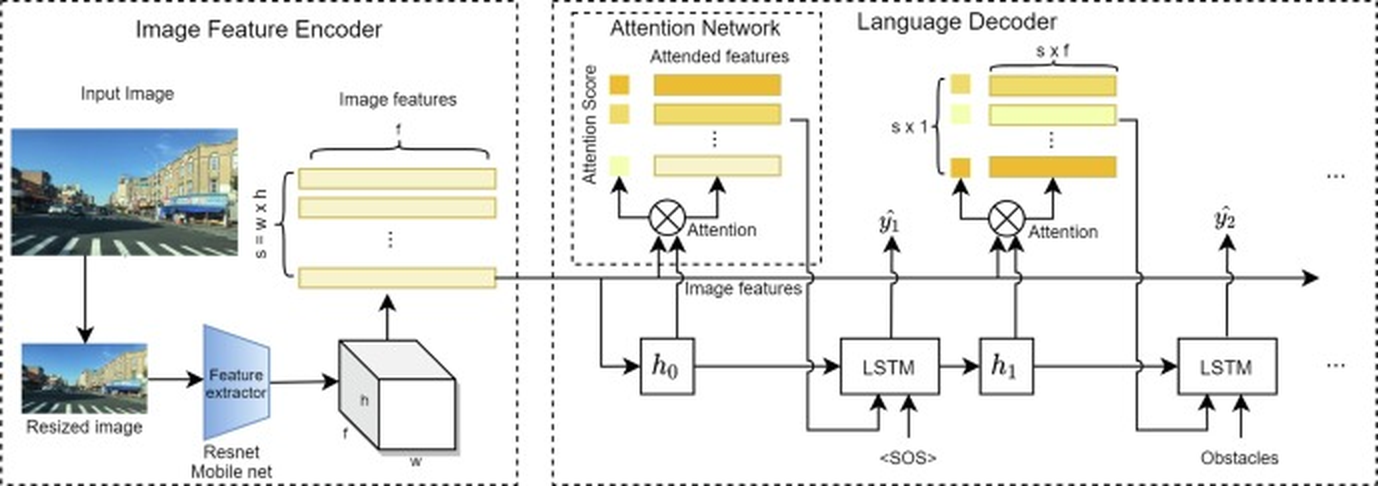
This diagram illustrates the architecture of an image captioning system, detailing the flow of information from an input image through an image feature encoder, attention network, and language decoder. The system appears to utilize a ResNet or MobileNet for feature extraction, an attention mechanism to focus on relevant image regions, and an LSTM-based decoder to generate a textual description.
### Components/Axes
The diagram is divided into three main sections: "Image Feature Encoder" (left), "Attention Network" (center), and "Language Decoder" (right).
* **Image Feature Encoder:** Includes components labeled "Input Image", "Resized Image", "Feature extractor", "Resnet Mobile net", "Image features", and dimensions "s = w x h".
* **Attention Network:** Contains "Attention Score", "Attended features", and an "Attention" operation (represented by a circled multiplication symbol).
* **Language Decoder:** Includes "LSTM", "h₀", "h₁", "<SOS>" (Start of Sentence), "y₁", "y₂", and "Obstacles".
* **Data Flow:** Arrows indicate the direction of information flow between components.
### Detailed Analysis or Content Details
The process begins with an "Input Image" which is then "Resized". The resized image is fed into a "Feature extractor" (ResNet or MobileNet), which outputs "Image features" with dimensions 's' (height) by 'w' (width) by 'h' (depth). These image features are then passed to the "Attention Network".
The "Attention Network" calculates an "Attention Score" and produces "Attended features". These attended features, along with the original "Image features", are fed into an LSTM within the "Language Decoder". The first LSTM receives the "<SOS>" token as input and produces a hidden state "h₀" and an output "y₁". This process is repeated with subsequent LSTMs, receiving the previous hidden state (e.g., "h₁") and the word "Obstacles" as input, generating "y₂", and so on. The outputs "y₁" and "y₂" are then fed back into the attention mechanism.
The diagram shows a repeating pattern of LSTM layers and attention mechanisms, suggesting a sequence generation process. The dimensions of the attended features are indicated as s x t, where 't' is likely the sequence length.
### Key Observations
* The architecture employs an attention mechanism, allowing the decoder to focus on different parts of the image when generating each word of the caption.
* The use of LSTM suggests a recurrent neural network approach to language modeling.
* The diagram highlights the key components of an image captioning system, providing a high-level overview of the data flow.
* The "Obstacles" input to the LSTM suggests the system may be designed to generate captions that specifically mention obstacles detected in the image.
### Interpretation
This diagram represents a typical encoder-decoder architecture for image captioning. The encoder (Image Feature Encoder) transforms the image into a fixed-length vector representation (image features). The decoder (Language Decoder) then uses this representation to generate a sequence of words (the caption). The attention mechanism bridges the gap between the encoder and decoder, allowing the decoder to selectively attend to different parts of the image when generating each word.
The inclusion of "Obstacles" as an input to the decoder suggests that the system is designed for a specific application, such as autonomous navigation or robotic perception, where identifying and describing obstacles is crucial. The diagram effectively illustrates the interplay between visual and linguistic information in the task of image captioning. The repeating LSTM structure indicates the system is capable of generating captions of variable length. The use of ResNet or MobileNet as the feature extractor suggests a focus on leveraging pre-trained models for efficient and accurate feature extraction.