TECHNICAL ASSET FINGERPRINT
1f559dccd3a32cdc8026fac1
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
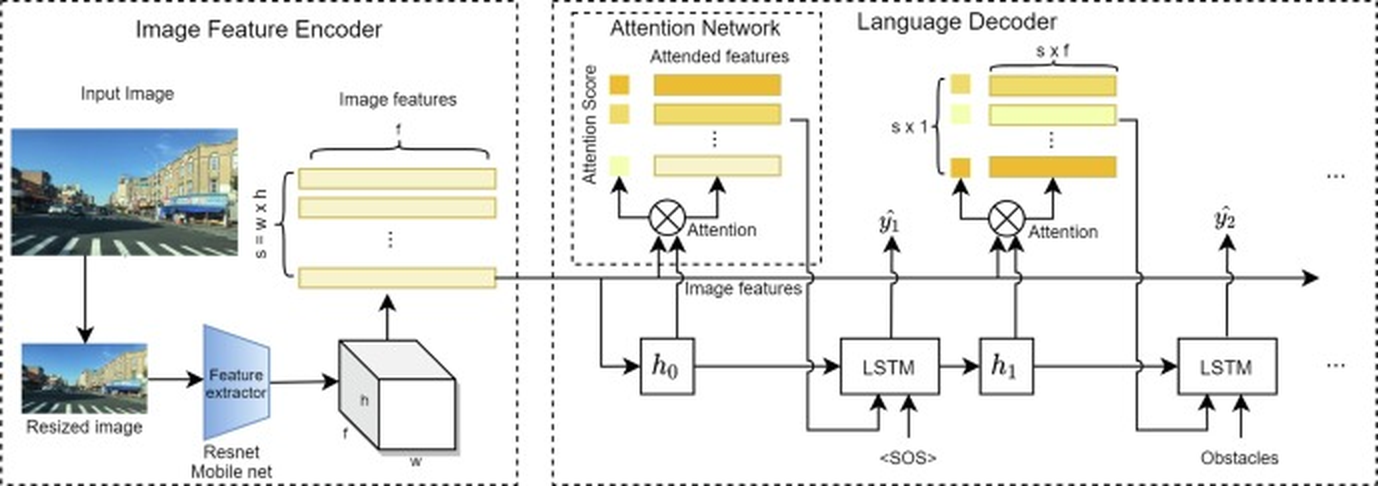
## Technical Diagram: Visual Attention-Based Image Captioning Architecture
### Overview
This image is a technical flowchart illustrating a neural network architecture for image captioning or visual question answering. The system processes an input image through a feature encoder, applies an attention mechanism, and uses a recurrent language decoder to generate a sequence of words. The diagram is divided into three main dashed-line boxes representing distinct processing stages.
### Components/Axes
The diagram is segmented into three primary regions from left to right:
1. **Image Feature Encoder (Left Box):**
* **Input Image:** A photograph of a street scene with buildings, a crosswalk, and a blue sky.
* **Resized image:** A smaller version of the input image.
* **Feature extractor:** A blue trapezoid labeled "Resnet Mobile net".
* **Output:** A 3D block representing a feature map with dimensions labeled `h` (height), `w` (width), and `f` (feature channels).
* **Image features:** A stack of horizontal yellow bars representing the flattened feature vectors. The total number of spatial locations is labeled `s = w x h`, and the feature dimension is `f`.
2. **Attention Network (Middle Box):**
* **Input:** The "Image features" from the encoder.
* **Attention Mechanism:** A circle with an 'X' labeled "Attention". It receives two inputs: the image features and a hidden state `h₀`.
* **Attention Score:** A vertical column of small yellow squares.
* **Attended features:** A stack of horizontal yellow bars, representing the context vector after attention is applied.
* **Output:** The attended features are passed to the Language Decoder.
3. **Language Decoder (Right Box):**
* **Recurrent Core:** A sequence of LSTM cells.
* **Initial Step:** The first LSTM receives the initial hidden state `h₀` and a start-of-sequence token `<SOS>`. It produces an output `ŷ₁` and a new hidden state `h₁`.
* **Subsequent Steps:** The next LSTM receives `h₁` and the previous output (implied). It also receives an input labeled "Obstacles" at the second step. It produces output `ŷ₂` and continues the sequence (indicated by `...`).
* **Attention Integration:** At each decoder step, an "Attention" mechanism (circle with 'X') combines the current LSTM hidden state with the original "Image features" to produce "Attended features" (yellow bars of dimension `s x f`), which are then used to predict the next word.
* **Output Symbols:** The predicted word tokens are labeled `ŷ₁`, `ŷ₂`, etc.
### Detailed Analysis
* **Data Flow:** The process is sequential and feed-forward with recurrent connections in the decoder.
1. An `Input Image` is resized and passed through a `Feature extractor` (ResNet or MobileNet).
2. This produces a 3D feature map (`h x w x f`), which is reshaped into `s` spatial vectors, each of dimension `f` (`s = w x h`).
3. These `Image features` are fed into the `Attention Network`.
4. The `Language Decoder` generates a word sequence. For each step `t`:
* The LSTM cell takes the previous hidden state `h_{t-1}` and the previous word embedding (or `<SOS>` for the first step).
* An `Attention` mechanism computes a weighted sum of the `Image features` using the current LSTM state, producing a context vector (`Attended features`).
* This context vector and the LSTM state are used to predict the next word `ŷ_t`.
* **Key Dimensions & Labels:**
* `s`: Total number of spatial locations in the feature map (`s = w x h`).
* `f`: Depth of the feature vector at each spatial location.
* `h, w`: Height and width of the intermediate feature map.
* `s x f`: Dimension of the attended feature vector for a single time step.
* `s x 1`: Dimension of the attention score vector (one score per spatial location).
* **Text Transcription:** All text is in English. Key labels include: "Image Feature Encoder", "Input Image", "Resized image", "Feature extractor", "Resnet Mobile net", "Image features", "Attention Network", "Attention Score", "Attended features", "Attention", "Language Decoder", "<SOS>", "Obstacles", "LSTM".
### Key Observations
1. **Modular Design:** The architecture cleanly separates visual feature extraction, attention-based fusion, and language generation.
2. **Attention Mechanism:** The diagram explicitly shows attention being applied at *every* step of the language decoder, allowing the model to focus on different parts of the image when generating each word.
3. **Specific Inputs:** The inclusion of an "Obstacles" input at the second LSTM step is notable. This suggests the model might be designed for a specific task like navigation instruction generation or visual question answering where external knowledge or a specific query is provided.
4. **Feature Extraction:** The use of "Resnet Mobile net" indicates a choice between a deeper (ResNet) or more efficient (MobileNet) convolutional backbone for feature extraction.
5. **Spatial Grounding:** The legend (color coding) is consistent: yellow bars represent feature vectors (both raw image features and attended features), and small yellow squares represent attention scores. The attention mechanism (circle with 'X') is consistently placed between the LSTM hidden state and the image features.
### Interpretation
This diagram represents a **soft attention-based encoder-decoder model** for generating textual descriptions from images. The core innovation highlighted is the dynamic alignment between the generated words and the relevant spatial regions of the image via the attention network.
* **What it demonstrates:** The model learns to "look at" specific parts of an image (e.g., the crosswalk, a building) when producing the corresponding word in a sentence (e.g., "crosswalk", "building"). The attention scores visualize this alignment process.
* **Relationships:** The Image Feature Encoder acts as the "eyes," converting pixels into a semantic feature space. The Language Decoder acts as the "mouth," producing sequential language. The Attention Network is the critical "bridge" or "focus mechanism" that allows the decoder to query the visual features at each step, making the generation process grounded and interpretable.
* **Notable Anomalies/Features:** The explicit "Obstacles" input is the most unique element. It implies this architecture is tailored for a downstream task requiring interaction with a list or description of obstacles, such as generating safe navigation paths for a robot or answering questions about hazards in a scene. This moves it beyond generic image captioning into a more goal-oriented visual reasoning system. The choice of LSTM over a Transformer decoder also suggests a design possibly focused on efficiency or a specific research context prior to the widespread adoption of Transformers.
DECODING INTELLIGENCE...