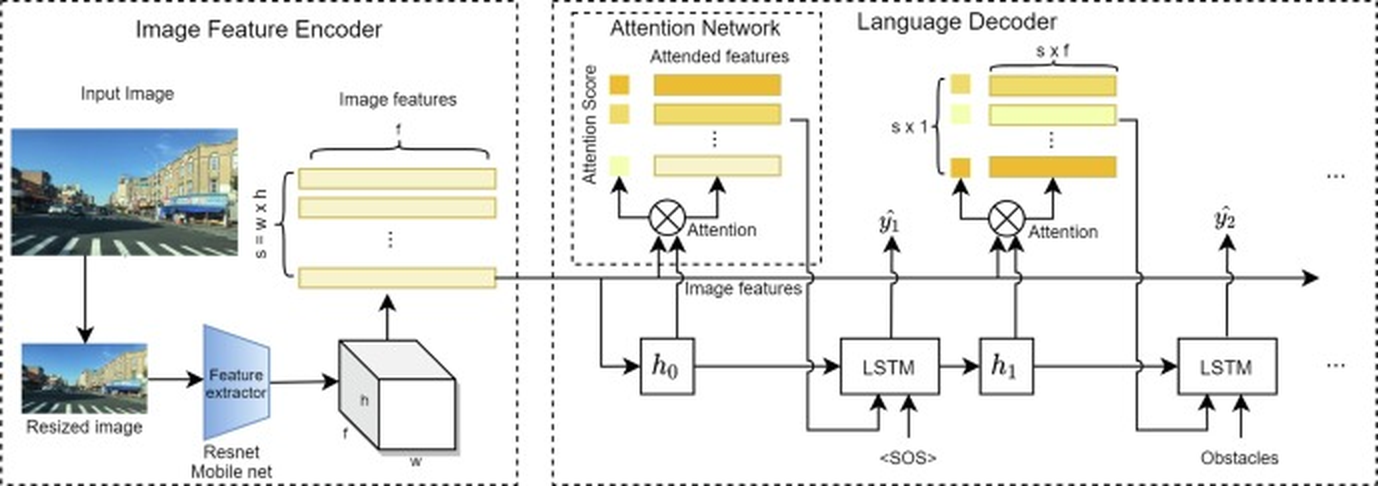
## Diagram: Multimodal Image-Language Processing Pipeline
### Overview
The diagram illustrates a technical architecture for processing visual and linguistic data. It consists of three interconnected modules: an **Image Feature Encoder**, an **Attention Network**, and a **Language Decoder**. The pipeline transforms an input image into a sequence of obstacle predictions using feature extraction, attention mechanisms, and recurrent neural networks.
---
### Components/Axes
#### Image Feature Encoder
- **Input Image**: A street scene with buildings, vehicles, and a crosswalk.
- **Resized Image**: Processed by a **Resnet Mobile net** feature extractor.
- **Image Features**: Output as a 3D tensor (`s x w x h`), representing spatial and channel dimensions.
#### Attention Network
- **Attention Score**: Computed via a weighted sum of image features (`s x f`).
- **Attended Features**: Weighted combination of original features using attention scores (colors: orange, yellow, light yellow).
- **Flow**: Image features → Attention Score → Attended Features.
#### Language Decoder
- **LSTM Layers**: Two sequential LSTM units (`h₀`, `h₁`) process attended features.
- **Output Sequence**: Generated obstacles (`y₁`, `y₂`, ...) prefixed with `<SOS>` (Start of Sentence).
- **Flow**: Attended Features → LSTM → Obstacles.
---
### Detailed Analysis
1. **Image Feature Encoder**:
- Input image is resized and fed into a **Resnet Mobile net** to extract spatial features (`s x w x h`).
- Features are flattened into a 2D matrix for further processing.
2. **Attention Network**:
- Attention scores are computed (orange/yellow gradients) to prioritize relevant image regions.
- Attended features are generated by element-wise multiplication of original features and attention scores.
3. **Language Decoder**:
- LSTM layers (`h₀`, `h₁`) process attended features sequentially.
- Output sequence starts with `<SOS>` and predicts obstacles (`y₁`, `y₂`, ...) autoregressively.
---
### Key Observations
- **Attention Mechanism**: Highlights critical image regions (e.g., vehicles, pedestrians) for obstacle detection.
- **LSTM Hierarchy**: Two LSTM layers suggest hierarchical temporal modeling of obstacle sequences.
- **Color Coding**: Attention scores use a gradient (orange > yellow > light yellow) to denote importance.
---
### Interpretation
This architecture integrates **computer vision** and **natural language processing** for scene understanding. The attention network acts as a bridge, focusing the language model on salient image features. The use of Resnet Mobile net ensures lightweight feature extraction for mobile deployment, while LSTMs handle sequential obstacle prediction. The diagram emphasizes **cross-modal alignment**, where visual and linguistic data are jointly optimized for tasks like autonomous navigation or image captioning.