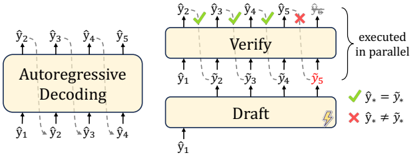
## Diagram: Parallel Verification vs. Autoregressive Decoding
### Overview
The image is a technical diagram comparing two sequence generation or decoding processes. On the left is a standard "Autoregressive Decoding" model. On the right is a two-stage process involving a "Draft" model and a "Verify" model, which operates in parallel. The diagram illustrates a method for accelerating sequence generation by using a draft model to propose multiple tokens, which are then verified simultaneously.
### Components/Axes
The diagram is divided into two main sections:
**1. Left Section: Autoregressive Decoding**
* **Central Component:** A rounded rectangle labeled **"Autoregressive Decoding"**.
* **Input (Bottom):** A sequence of tokens labeled **ŷ₁, ŷ₂, ŷ₃, ŷ₄**. Arrows point upward from these into the central component.
* **Output (Top):** A sequence of tokens labeled **ŷ₂, ŷ₃, ŷ₄, ŷ₅**. Arrows point upward from the central component to these tokens. This represents the sequential, one-token-at-a-time generation process.
**2. Right Section: Draft & Verify (Parallel Execution)**
* **Components:** Two stacked rounded rectangles.
* The bottom rectangle is labeled **"Draft"**. It has a small icon of a quill pen (✍️) in its bottom-right corner.
* The top rectangle is labeled **"Verify"**.
* **Flow & Labels:**
* **Input to Draft (Bottom):** A single token labeled **ŷ₁**. An arrow points upward into the "Draft" box.
* **Draft Output / Verify Input:** A sequence of tokens labeled **y₁, ŷ₂, ŷ₃, ŷ₄, ŷ₅**. Arrows point upward from the "Draft" box to the "Verify" box.
* **Verify Output (Top):** A sequence of tokens labeled **ŷ₂, ŷ₃, ŷ₄, ŷ₅, ŷ₆**. Arrows point upward from the "Verify" box.
* **Verification Symbols:** Above the output tokens, symbols indicate the verification result for each:
* **ŷ₂:** Green checkmark (✓)
* **ŷ₃:** Green checkmark (✓)
* **ŷ₄:** Green checkmark (✓)
* **ŷ₅:** Red cross (✗)
* **ŷ₆:** Red cross (✗)
* **Annotation:** A curly brace to the right of the "Verify" box is labeled **"executed in parallel"**.
* **Legend (Bottom-Right):**
* A green checkmark (✓) is defined as: **ŷₓ = yₓ** (The draft token matches the verified token).
* A red cross (✗) is defined as: **ŷₓ ≠ yₓ** (The draft token does not match the verified token).
### Detailed Analysis
The diagram contrasts two computational pathways for generating a sequence of tokens (ŷ).
* **Autoregressive Decoding (Left):** This is a sequential process. Starting from an initial token (ŷ₁), the model generates the next token (ŷ₂), then uses that to generate the next (ŷ₃), and so on. The output tokens (ŷ₂-ŷ₅) are generated one after the other in a chain.
* **Draft & Verify (Right):** This is a speculative or parallel decoding process.
1. **Draft Stage:** A (presumably faster or less accurate) "Draft" model takes an initial token (ŷ₁) and generates a sequence of candidate tokens in one pass: **y₁, ŷ₂, ŷ₃, ŷ₄, ŷ₅**. Note that the first draft token is labeled `y₁`, distinct from the input `ŷ₁`.
2. **Verify Stage:** A (presumably more accurate) "Verify" model processes all draft tokens **in parallel**. It checks each draft token against what it would have generated.
3. **Results:** The first three draft tokens (ŷ₂, ŷ₃, ŷ₄) are accepted (✓), meaning the Verify model agrees with them (`ŷₓ = yₓ`). The last two draft tokens (ŷ₅, ŷ₆) are rejected (✗), meaning the Verify model disagrees (`ŷₓ ≠ yₓ`). The final output sequence from this process is the accepted tokens plus any new tokens generated to replace the rejected ones (the diagram shows ŷ₆ as a new, rejected output).
### Key Observations
1. **Parallelism:** The core innovation highlighted is the parallel execution in the "Verify" stage, contrasting with the strictly sequential nature of standard autoregressive decoding.
2. **Speculative Execution:** The "Draft" model speculatively generates multiple future tokens. This is efficient if the draft model is correct often, as multiple tokens can be validated in a single parallel step.
3. **Acceptance/Rejection Mechanism:** The system has a clear gating mechanism. Accepted tokens (✓) are kept, while rejected tokens (✗) must be recomputed, likely falling back to a sequential step.
4. **Token Labeling Nuance:** The use of `y` for draft tokens and `ŷ` for input/output/verified tokens suggests a distinction between proposed and confirmed values. The legend explicitly defines the equality check between them.
### Interpretation
This diagram illustrates a **speculative decoding** or **draft-verification** architecture, a technique used to accelerate large language model (LLM) inference.
* **What it demonstrates:** The method aims to break the sequential bottleneck of autoregressive generation. By using a smaller, faster "draft" model to propose a block of text and a larger, more accurate "verify" model to check that block in parallel, the system can potentially generate multiple correct tokens per verification step, increasing overall throughput.
* **Relationships:** The "Draft" and "Verify" models are coupled. The draft model's utility depends on its alignment with the verify model. The "executed in parallel" annotation is the key differentiator from the left-side process.
* **Notable Patterns/Anomalies:** The pattern of three accepts followed by two rejects is illustrative. It shows that the draft model's accuracy may degrade for tokens further into the future (a longer "horizon"). The system's efficiency gain is directly tied to the draft model's acceptance rate; a high rate means most parallel verifications succeed, yielding significant speedup. A low rate would cause frequent rollbacks, diminishing the benefit. The diagram effectively visualizes the trade-off between speculative parallelism and verification overhead.