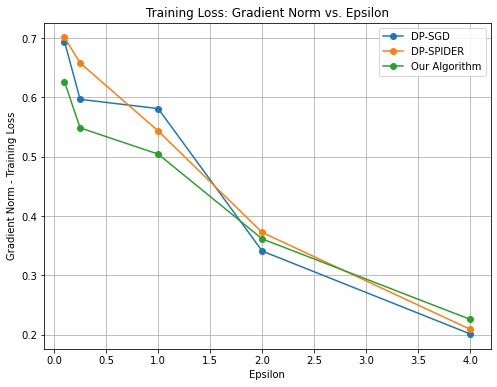
# Technical Document Extraction: Training Loss Chart
## Title
**Training Loss: Gradient Norm vs. Epsilon**
## Axes Labels
- **X-axis**: Epsilon (ranging from 0.0 to 4.0 in increments of 0.5)
- **Y-axis**: Gradient Norm - Training Loss (ranging from 0.2 to 0.7 in increments of 0.1)
## Legend
- **DP-SGD**: Blue line with circular markers
- **DP-SPIDER**: Orange line with circular markers
- **Our Algorithm**: Green line with circular markers
## Data Points
### DP-SGD (Blue)
- (0.0, 0.7)
- (0.5, 0.6)
- (1.0, 0.58)
- (2.0, 0.34)
- (3.0, 0.28)
- (4.0, 0.2)
### DP-SPIDER (Orange)
- (0.0, 0.7)
- (0.5, 0.65)
- (1.0, 0.54)
- (2.0, 0.37)
- (3.0, 0.30)
- (4.0, 0.21)
### Our Algorithm (Green)
- (0.0, 0.62)
- (0.5, 0.55)
- (1.0, 0.50)
- (2.0, 0.36)
- (3.0, 0.32)
- (4.0, 0.22)
## Key Trends
1. **General Behavior**: All three algorithms exhibit a decreasing trend in gradient norm as epsilon increases.
2. **Initial Values**:
- DP-SGD and DP-SPIDER start at the highest gradient norm (0.7) at epsilon = 0.0.
- Our Algorithm starts slightly lower (0.62) at epsilon = 0.0.