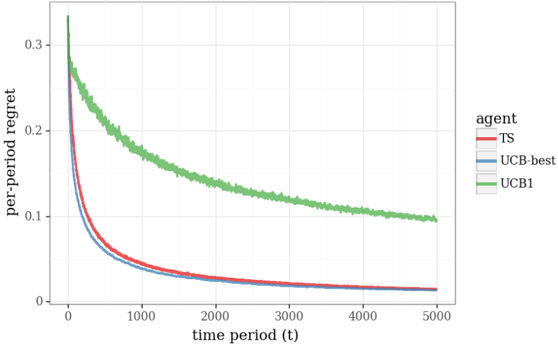
## Line Graph: Per-Period Regret Over Time
### Overview
The image depicts a line graph comparing the per-period regret of three agents (TS, UCB-best, UCB1) across 5,000 time periods. All three lines show a decreasing trend, with TS and UCB-best converging rapidly to low regret values, while UCB1 declines more gradually.
### Components/Axes
- **X-axis**: "time period (t)" with increments of 1,000 (0 to 5,000).
- **Y-axis**: "per-period regret" scaled from 0 to 0.3 in 0.1 increments.
- **Legend**: Located in the top-right corner, associating:
- Red line: TS
- Blue line: UCB-best
- Green line: UCB1
### Detailed Analysis
- **TS (Red Line)**:
- Starts at ~0.3 at t=0.
- Drops sharply to ~0.05 by t=1,000.
- Flattens near ~0.01 by t=5,000.
- **UCB-best (Blue Line)**:
- Mirrors TS closely, starting at ~0.3.
- Declines to ~0.05 by t=1,000.
- Stabilizes near ~0.01 by t=5,000.
- **UCB1 (Green Line)**:
- Begins at ~0.3.
- Declines gradually to ~0.1 by t=3,000.
- Reaches ~0.01 by t=5,000.
### Key Observations
1. **Rapid Convergence**: TS and UCB-best achieve near-minimal regret (~0.01) by t=5,000, outperforming UCB1.
2. **UCB1 Lag**: UCB1’s regret decreases at half the rate of TS/UCB-best, remaining ~0.1 at t=2,000.
3. **Initial Overlap**: All agents start with identical regret values at t=0.
### Interpretation
The data suggests that TS and UCB-best agents optimize regret reduction more efficiently than UCB1, likely due to superior exploration-exploitation strategies. UCB1’s slower decline implies a more conservative approach, potentially prioritizing stability over rapid adaptation. The convergence of TS and UCB-best indicates similar algorithmic effectiveness in minimizing regret over time.