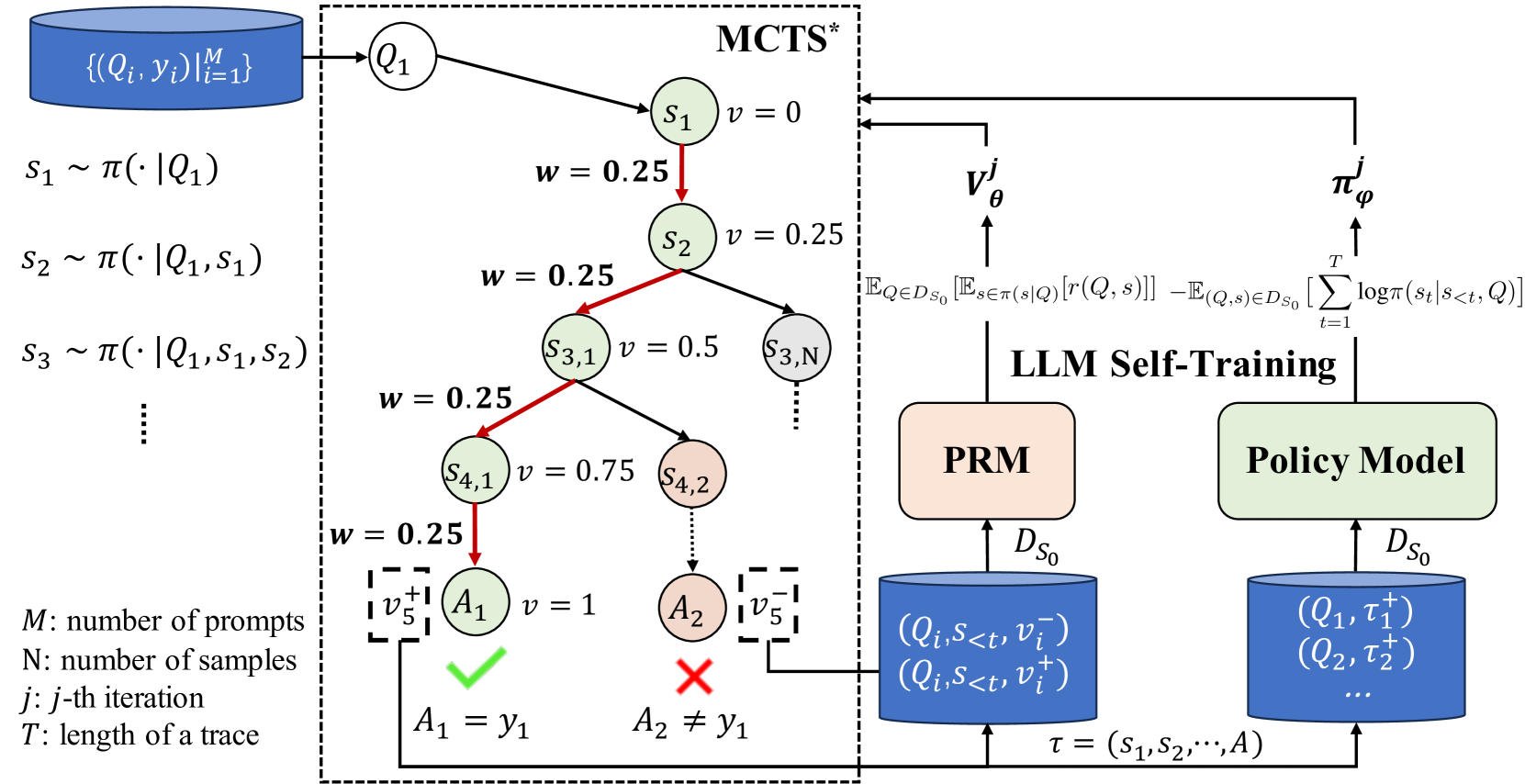
## Diagram: MCTS*-Based LLM Self-Training Framework
### Overview
This image is a technical diagram illustrating a machine learning training pipeline that combines Monte Carlo Tree Search (MCTS*) with Large Language Model (LLM) self-training. The system uses a dataset of prompts and responses to generate reasoning traces via MCTS, evaluates them with a Process Reward Model (PRM), and updates a Policy Model. The diagram is divided into three main regions: a left-side data input and sampling section, a central MCTS* tree search process, and a right-side LLM self-training loop.
### Components/Axes
**Left Region (Data Input & Sampling):**
- **Top-left blue cylinder:** Labeled `{(Q_i, y_i)}|_{i=1}^{M}`. This represents a dataset of `M` prompt-response pairs.
- **Sampling equations below the cylinder:**
- `s_1 ~ π(· | Q_1)`
- `s_2 ~ π(· | Q_1, s_1)`
- `s_3 ~ π(· | Q_1, s_1, s_2)`
- A vertical ellipsis (`⋮`) indicates continuation.
- **Legend (bottom-left):**
- `M`: number of prompts
- `N`: number of samples
- `j`: j-th iteration
- `T`: length of a trace
**Central Region (MCTS* Tree Search):**
- Enclosed in a dashed box labeled **MCTS*** at the top.
- **Tree Structure:**
- Root node: `Q_1` (circle).
- First level: Node `s_1` with value `v = 0`.
- A red arrow points from `s_1` to `s_2` with weight `w = 0.25`.
- Node `s_2` has value `v = 0.25`.
- From `s_2`, a red arrow points to node `s_{3,1}` with `w = 0.25` and `v = 0.5`. Another branch (black arrow) points to node `s_{3,N}`.
- From `s_{3,1}`, a red arrow points to node `s_{4,1}` with `w = 0.25` and `v = 0.75`. Another branch points to node `s_{4,2}`.
- From `s_{4,1}`, a red arrow points to terminal node `A_1` with `w = 0.25` and `v = 1`. A green checkmark (✓) is below it, with the label `A_1 = y_1`.
- From `s_{4,2}`, a dotted line points to terminal node `A_2`. A red cross (✗) is below it, with the label `A_2 ≠ y_1`.
- **Value Feedback Boxes:**
- A dashed box labeled `v_5^+` is connected to `A_1`.
- A dashed box labeled `v_5^-` is connected to `A_2`.
**Right Region (LLM Self-Training):**
- Labeled **LLM Self-Training** at the top.
- **Two main model blocks:**
1. **PRM** (peach-colored rectangle): Process Reward Model.
2. **Policy Model** (light green rectangle).
- **Equations above the models:**
- Above PRM: `E_{Q∈D_{S_0}}[E_{s∈π(s|Q)}[r(Q, s)]]`
- Above Policy Model: `-E_{(Q,s)∈D_{S_0}}[∑_{t=1}^{T} log π(s_t | s_{<t}, Q)]`
- **Data Stores (blue cylinders):**
- **Left cylinder (feeds PRM):** Labeled `D_{S_0}`. Contains tuples: `(Q_i, s_{<t}, v_i^-)` and `(Q_i, s_{<t}, v_i^+)`.
- **Right cylinder (feeds Policy Model):** Labeled `D_{S_0}`. Contains tuples: `(Q_1, τ_1^+)`, `(Q_2, τ_2^+)`, and a vertical ellipsis (`...`).
- **Trace Input:** A trace `τ = (s_1, s_2, ..., A)` is shown at the bottom, with arrows pointing into both blue data store cylinders.
- **Model Outputs:**
- An arrow from PRM points upward to `V_θ^j`.
- An arrow from Policy Model points upward to `π_φ^j`.
- Both `V_θ^j` and `π_φ^j` have arrows pointing back into the MCTS* box, indicating they are used in the search process.
### Detailed Analysis
**Flow and Relationships:**
1. **Initialization:** The process starts with a dataset of prompts (`Q_i`) and correct answers (`y_i`).
2. **MCTS* Exploration:** For a given prompt `Q_1`, the MCTS* algorithm explores a tree of reasoning steps (`s_1, s_2, ...`). Each step is sampled from a policy `π`. The tree assigns a value `v` (increasing from 0 to 1 along the successful path) and a weight `w` (consistently 0.25 on the highlighted red path).
3. **Outcome Evaluation:** The search terminates at actions `A_1` (correct, matches `y_1`) and `A_2` (incorrect). These generate positive (`v_5^+`) and negative (`v_5^-`) reward signals.
4. **Data Collection:** The generated traces (`τ`), states (`s_{<t}`), and reward signals are stored in the `D_{S_0}` datasets.
5. **Model Training:**
- The **PRM** is trained on state-reward pairs to learn a value function `V_θ^j`.
- The **Policy Model** is trained on successful traces (`τ^+`) to improve its action selection, resulting in policy `π_φ^j`.
6. **Feedback Loop:** The updated value function (`V_θ^j`) and policy (`π_φ^j`) are fed back into the MCTS* process for the next iteration (`j`), creating a self-improving loop.
### Key Observations
- The **red arrows** in the MCTS* tree highlight a specific, high-value path from the root to the correct answer `A_1`.
- The **weight `w`** is constant at 0.25 along this highlighted path, suggesting a uniform sampling or exploration strategy within this branch.
- The **value `v`** increases monotonically (0 → 0.25 → 0.5 → 0.75 → 1) along the successful path, indicating the model's growing confidence or the reward accumulation.
- The diagram explicitly separates **process-level rewards** (handled by PRM, which evaluates intermediate states `s`) from **outcome-level rewards** (the final correct/incorrect check).
- The **Policy Model** is trained only on positive traces (`τ^+`), while the **PRM** is trained on both positive and negative state-reward pairs.
### Interpretation
This diagram depicts a sophisticated **reinforcement learning from AI feedback (RLAIF)** or **self-play** framework for reasoning. The core idea is to use a search algorithm (MCTS*) to generate diverse reasoning paths for a given problem. These paths are then automatically evaluated—both at intermediate steps (by the PRM) and at the final outcome—to create a training signal without human labeling.
The system demonstrates a **closed-loop improvement cycle**: the model's own outputs (traces) and their automated evaluation are used to train better versions of its components (value function and policy), which in turn guide more effective future search. This approach aims to enhance the LLM's ability to perform multi-step reasoning, exploration, and self-correction. The use of MCTS* suggests an emphasis on balancing exploration of new reasoning paths with exploitation of known good ones. The clear separation of the PRM (which learns *what* is a good step) and the Policy Model (which learns *how* to generate such steps) is a key architectural insight for scalable self-improvement.