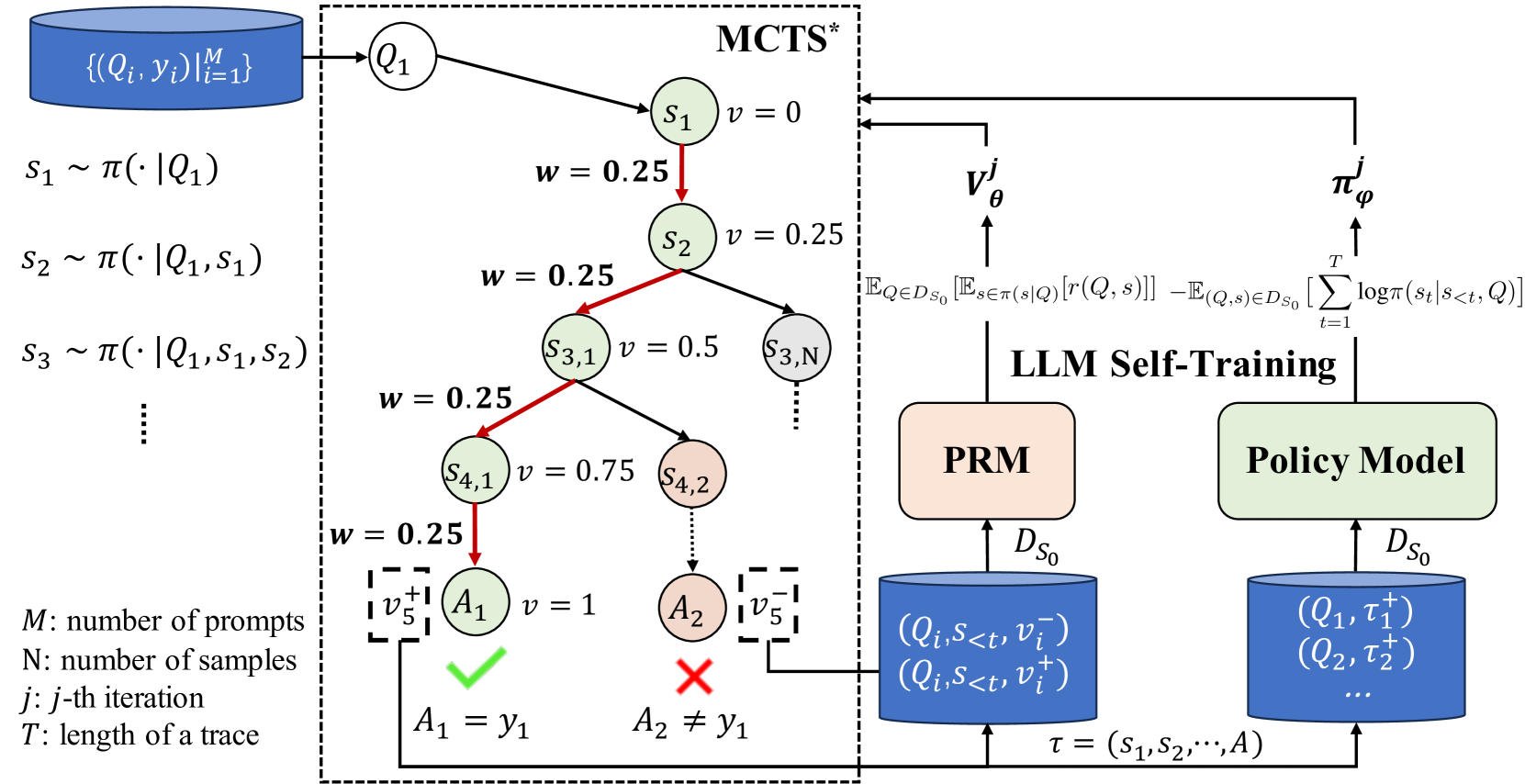
## Technical Diagram: Multi-Stage Decision Process with LLM Self-Training
### Overview
The diagram illustrates a multi-stage decision-making process involving Monte Carlo Tree Search (MCTS*), LLM self-training, and policy modeling. It combines probabilistic state transitions, reward modeling, and policy optimization in a hierarchical framework. Key components include a prompt database, MCTS* search tree, reward model (PRM), and policy model with self-training loops.
### Components/Axes
1. **Left Panel (MCTS* Search Tree)**
- **Input**: Blue cylinder labeled `{(Q_i, y_i)}_i=1^M` (dataset of prompts and ground truths)
- **State Generation**: Sequential states `S₁ ~ π(·|Q₁)`, `S₂ ~ π(·|Q₁,S₁)`, `S₃ ~ π(·|Q₁,S₁,S₂)`, etc.
- **Search Nodes**:
- `S₁` (v=0) → `S₂` (v=0.25) → `S₃,₁` (v=0.5) → `S₃,₃` (v=0.75)
- `S₄,₁` (v=0.75) → `A₁` (v=1, ✓) and `A₂` (v=0.5, ✗)
- **Weights**: All edges labeled `w=0.25` except final reward edges (v=1 or 0.5)
- **Terminal Nodes**:
- `A₁` (correct action, green checkmark)
- `A₂` (incorrect action, red cross)
2. **Right Panel (LLM Self-Training)**
- **Reward Model (PRM)**:
- Input: `D_S₀` (database of `(Q_i, S_<t, v_i^-)` and `(Q_i, S_<t, v_i^+)`)
- Output: `v'_θ` (reward prediction)
- **Policy Model**:
- Input: `D_S₀` (database of `(Q_i, τ_i^+)`)
- Output: `π'_φ` (policy update)
- **Equations**:
- `v'_θ = E_{Q∈D_S₀}[E_{s∈π(s|Q)}[r(Q,s)]] - E_{(Q,s)∈D_S₀}[∑_{t=1}^T logπ(s_t|s_<t, Q)]`
- `π'_φ` (policy update rule)
3. **Legend/Annotations**
- `M`: Number of prompts
- `N`: Number of samples
- `j`: Iteration index
- `T`: Trace length
- `τ = (s₁, s₂, ..., A)`: Trace definition
### Spatial Grounding
- **Left Panel**: Vertical flow from prompt database to MCTS* search tree
- **Right Panel**: Horizontal flow from PRM to Policy Model
- **Color Coding**:
- Blue: Databases (`D_S₀`, prompt set)
- Green: Correct actions (`A₁`)
- Red: Incorrect actions (`A₂`)
- Gray: Intermediate states/nodes
### Detailed Analysis
1. **MCTS* Process**
- Starts with prompt `Q₁` and generates states via policy `π`
- Nodes have value estimates (`v`) updated through backpropagation
- Final actions (`A₁`, `A₂`) evaluated with binary rewards (v=1/0.5)
2. **Reward Modeling**
- PRM learns reward function `r(Q,s)` using dataset `D_S₀`
- Combines expected reward with entropy regularization
3. **Policy Optimization**
- Policy model updates using trajectory data `(Q_i, τ_i^+)`
- Traces include state sequences and final actions
### Key Observations
1. **Weight Consistency**: All MCTS* edges share uniform weight `w=0.25` except terminal rewards
2. **Reward Signal**: Final actions have explicit success/failure indicators (✓/✗)
3. **Self-Training Loop**: PRM and Policy Model share the same database `D_S₀`
4. **Trace Definition**: Explicitly defines `τ` as state-action sequence
### Interpretation
This diagram represents a hybrid reinforcement learning framework where:
1. **MCTS* Exploration**: Guides action selection through probabilistic state expansion
2. **Reward Learning**: PRM quantifies action quality using both expected rewards and policy entropy
3. **Policy Refinement**: Self-training loop improves policy using successful trajectories
4. **Data Flow**: Prompts → MCTS* search → Reward estimation → Policy update
The uniform edge weights suggest a simplified exploration strategy, while the binary reward indicators at terminal nodes imply a focus on final action correctness. The shared database `D_S₀` enables cross-component learning, with the policy model specializing in successful trajectories while the reward model generalizes across all states.