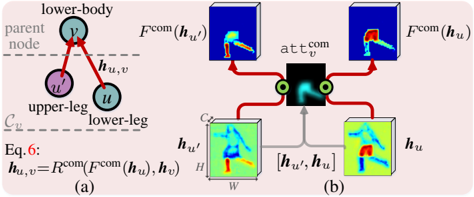
## Diagram: Hierarchical Compositional Reasoning
### Overview
The image presents a diagram illustrating a hierarchical compositional reasoning process, likely within a computer vision or machine learning context. It shows how features from different parts of an object (e.g., body parts) are combined to form a higher-level representation. The diagram is split into two parts: (a) a graph representation of the hierarchy and (b) a visual representation of the feature combination process.
### Components/Axes
**Part (a): Graph Representation**
* **Nodes:**
* `v`: Labeled "lower-body", representing a parent node.
* `u'`: Labeled "upper-leg", representing a child node.
* `u`: Labeled "lower-leg", representing a child node.
* **Edges:** Red arrows indicating the flow of information from child nodes to the parent node. The edges are labeled `h_u,v`.
* **Labels:**
* "parent node" (horizontal dashed line)
* "C_v" (horizontal dashed line)
* **Equation:**
* `Eq. 6: h_u,v = R^{com}(F^{com}(h_u'), h_v)`
**Part (b): Feature Combination Process**
* **Input Features:**
* `h_u'`: A 3D block labeled with dimensions `C`, `H`, and `W`, showing a human figure.
* `h_u`: A 3D block showing a human figure.
* **Feature Transformation:**
* `F^{com}(h_u')`: A 3D block showing a transformed representation of the human figure.
* `F^{com}(h_u)`: A 3D block showing a transformed representation of the human figure.
* **Attention Mechanism:**
* `att_v^{com}`: A block representing an attention mechanism, taking `[h_u', h_u]` as input.
* **Connections:** Red arrows indicate the flow of information. Gray arrows indicate the concatenation of `h_u'` and `h_u`.
### Detailed Analysis
**Part (a): Graph Representation**
The graph shows a hierarchical structure where the "lower-body" node (`v`) receives information from the "upper-leg" (`u'`) and "lower-leg" (`u`) nodes. The equation `h_u,v = R^{com}(F^{com}(h_u'), h_v)` describes how the features from the child nodes are combined to form a representation for the parent node. `R^{com}` likely represents a combination function, and `F^{com}` likely represents a feature transformation function.
**Part (b): Feature Combination Process**
The feature combination process visually demonstrates how the input features `h_u'` and `h_u` are transformed using `F^{com}`. The attention mechanism `att_v^{com}` takes the concatenated features `[h_u', h_u]` as input and likely assigns weights to the transformed features `F^{com}(h_u')` and `F^{com}(h_u)` before combining them.
The 3D blocks representing the features show human figures, suggesting that the process is related to human pose estimation or action recognition. The color gradients within the blocks likely represent feature activations or importance.
### Key Observations
* The diagram illustrates a hierarchical approach to feature representation.
* An attention mechanism is used to weigh the contributions of different features.
* The process is likely applied to human pose estimation or action recognition.
### Interpretation
The diagram demonstrates a hierarchical compositional reasoning process where features from different parts of an object are combined to form a higher-level representation. The use of an attention mechanism allows the model to focus on the most relevant features when combining them. This approach is likely to be more robust and accurate than simply concatenating the features. The hierarchical structure allows the model to capture relationships between different parts of the object, which is important for understanding complex scenes. The equation in part (a) provides a mathematical description of the feature combination process, while the visual representation in part (b) provides a more intuitive understanding of how the process works.