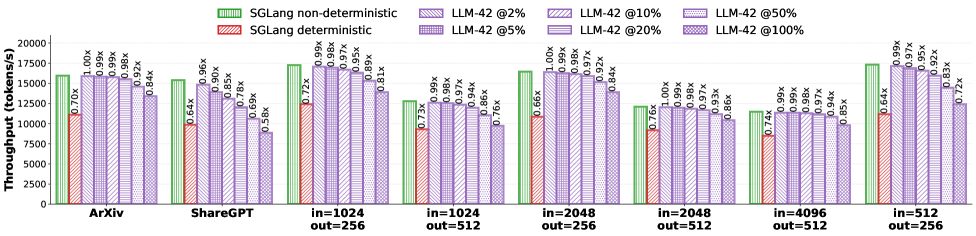
## Bar Chart: Throughput Comparison of SGLang and LLM-42
### Overview
The image is a bar chart comparing the throughput (tokens/s) of SGLang (deterministic and non-deterministic) and LLM-42 at different parameter settings (2%, 5%, 10%, 20%, 50%, and 100%). The throughput is evaluated across different input/output sizes and datasets (ArXiv, ShareGPT).
### Components/Axes
* **Y-axis:** Throughput (tokens/s), ranging from 0 to 20000, with tick marks at 2500 increments.
* **X-axis:** Categorical axis representing different datasets and input/output sizes: ArXiv, ShareGPT, in=1024 out=256, in=1024 out=512, in=2048 out=256, in=2048 out=512, in=4096 out=512, in=512 out=256.
* **Legend (top-left):**
* Green: SGLang non-deterministic
* Red: SGLang deterministic
* Purple with diagonal lines: LLM-42 @2%
* Purple with horizontal lines: LLM-42 @5%
* Purple with vertical lines: LLM-42 @10%
* Purple with forward-leaning diagonal lines: LLM-42 @20%
* Purple with backward-leaning diagonal lines: LLM-42 @50%
* Purple with a grid pattern: LLM-42 @100%
### Detailed Analysis
**ArXiv:**
* SGLang non-deterministic: ~16000 tokens/s
* SGLang deterministic: ~11200 tokens/s (0.70x relative to SGLang non-deterministic)
* LLM-42 @2%: ~16000 tokens/s (1.00x)
* LLM-42 @5%: ~15840 tokens/s (0.99x)
* LLM-42 @10%: ~15840 tokens/s (0.99x)
* LLM-42 @20%: ~15680 tokens/s (0.98x)
* LLM-42 @50%: ~14720 tokens/s (0.92x)
* LLM-42 @100%: ~13440 tokens/s (0.84x)
**ShareGPT:**
* SGLang non-deterministic: ~16000 tokens/s
* SGLang deterministic: ~10240 tokens/s (0.64x)
* LLM-42 @2%: ~14400 tokens/s (0.90x)
* LLM-42 @5%: ~13600 tokens/s (0.85x)
* LLM-42 @10%: ~11040 tokens/s (0.69x)
* LLM-42 @20%: ~9280 tokens/s (0.58x)
* LLM-42 @50%: ~15360 tokens/s (0.96x)
**in=1024 out=256:**
* SGLang non-deterministic: ~17600 tokens/s
* SGLang deterministic: ~12672 tokens/s (0.72x)
* LLM-42 @2%: ~17424 tokens/s (0.99x)
* LLM-42 @5%: ~17248 tokens/s (0.98x)
* LLM-42 @10%: ~17072 tokens/s (0.97x)
* LLM-42 @20%: ~16640 tokens/s (0.95x)
* LLM-42 @50%: ~15664 tokens/s (0.89x)
* LLM-42 @100%: ~14256 tokens/s (0.81x)
**in=1024 out=512:**
* SGLang non-deterministic: ~11500 tokens/s
* SGLang deterministic: ~8400 tokens/s (0.73x)
* LLM-42 @2%: ~11400 tokens/s (0.99x)
* LLM-42 @5%: ~11300 tokens/s (0.98x)
* LLM-42 @10%: ~11200 tokens/s (0.97x)
* LLM-42 @20%: ~10800 tokens/s (0.94x)
* LLM-42 @50%: ~9900 tokens/s (0.86x)
* LLM-42 @100%: ~8700 tokens/s (0.76x)
**in=2048 out=256:**
* SGLang non-deterministic: ~16000 tokens/s
* SGLang deterministic: ~10560 tokens/s (0.66x)
* LLM-42 @2%: ~16000 tokens/s (1.00x)
* LLM-42 @5%: ~15840 tokens/s (0.99x)
* LLM-42 @10%: ~15680 tokens/s (0.98x)
* LLM-42 @20%: ~15520 tokens/s (0.97x)
* LLM-42 @50%: ~14720 tokens/s (0.92x)
* LLM-42 @100%: ~13440 tokens/s (0.84x)
**in=2048 out=512:**
* SGLang non-deterministic: ~12000 tokens/s
* SGLang deterministic: ~9120 tokens/s (0.76x)
* LLM-42 @2%: ~12000 tokens/s (1.00x)
* LLM-42 @5%: ~11900 tokens/s (0.99x)
* LLM-42 @10%: ~11800 tokens/s (0.98x)
* LLM-42 @20%: ~11600 tokens/s (0.97x)
* LLM-42 @50%: ~11200 tokens/s (0.93x)
* LLM-42 @100%: ~10320 tokens/s (0.86x)
**in=4096 out=512:**
* SGLang non-deterministic: ~16000 tokens/s
* SGLang deterministic: ~11840 tokens/s (0.74x)
* LLM-42 @2%: ~15840 tokens/s (0.99x)
* LLM-42 @5%: ~15840 tokens/s (0.99x)
* LLM-42 @10%: ~15680 tokens/s (0.98x)
* LLM-42 @20%: ~15520 tokens/s (0.97x)
* LLM-42 @50%: ~15040 tokens/s (0.94x)
* LLM-42 @100%: ~13600 tokens/s (0.85x)
**in=512 out=256:**
* SGLang non-deterministic: ~17600 tokens/s
* SGLang deterministic: ~10240 tokens/s (0.64x)
* LLM-42 @2%: ~17424 tokens/s (0.99x)
* LLM-42 @5%: ~17072 tokens/s (0.97x)
* LLM-42 @10%: ~16640 tokens/s (0.95x)
* LLM-42 @20%: ~16224 tokens/s (0.92x)
* LLM-42 @50%: ~14576 tokens/s (0.83x)
* LLM-42 @100%: ~12672 tokens/s (0.72x)
### Key Observations
* SGLang non-deterministic generally has higher throughput than SGLang deterministic across all datasets and input/output sizes.
* LLM-42 throughput decreases as the parameter setting increases from 2% to 100%.
* The performance difference between LLM-42 at 2% and SGLang non-deterministic is minimal in most cases.
* The deterministic version of SGLang has significantly lower throughput than the non-deterministic version.
* The throughput varies depending on the input and output sizes.
### Interpretation
The bar chart illustrates the performance comparison between SGLang and LLM-42 under different conditions. The data suggests that SGLang non-deterministic and LLM-42 at lower parameter settings (e.g., 2%) achieve comparable throughput. As the parameter setting of LLM-42 increases, the throughput decreases, indicating a trade-off between model size/complexity and processing speed. The deterministic version of SGLang consistently underperforms compared to its non-deterministic counterpart, suggesting potential optimizations in the non-deterministic implementation. The input and output sizes also play a crucial role in determining the throughput, highlighting the importance of considering these factors when evaluating the performance of these models. The relative values (e.g., 0.70x) indicate the performance ratio compared to SGLang non-deterministic, providing a normalized view of the performance differences.