TECHNICAL ASSET FINGERPRINT
219db2ef5d6715634827e41f
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemma-3-27b-it-free VERSION 1
RUNTIME: google-free/gemma-3-27b-it
INTEL_VERIFIED
\n
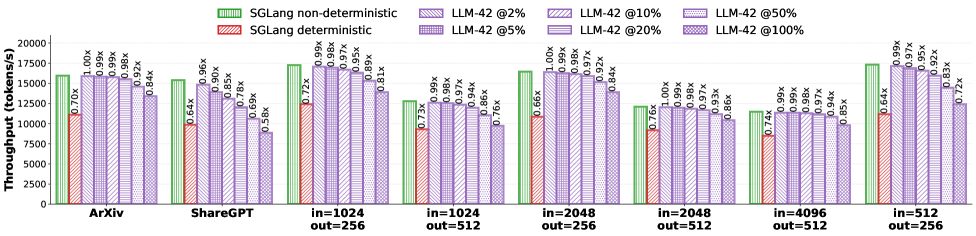
## Bar Chart: Throughput Comparison of Language Models
### Overview
This bar chart compares the throughput (tokens/s) of different language models (SGLang and LLM-42) under various conditions. The conditions vary by dataset (ArXiv, ShareGPT, and different input/output token lengths) and LLM-42's percentage of non-deterministic behavior (2%, 5%, 10%, 20%, 50%, 100%). The chart uses grouped bar representations to show the throughput of deterministic and non-deterministic SGLang, and different levels of non-determinism in LLM-42. Values are shown above each bar, representing a ratio relative to a baseline.
### Components/Axes
* **X-axis:** Represents the different datasets and input/output token length combinations. The categories are: "ArXiv", "ShareGPT", "in=1024 out=256", "in=1024 out=512", "in=2048 out=256", "in=2048 out=512", "in=4096 out=256", "in=4096 out=512".
* **Y-axis:** Represents Throughput in tokens/s, ranging from 0 to 20000.
* **Legend:** Located at the top-right of the chart. It defines the colors used for each data series:
* Light Green: SGLang non-deterministic
* Light Purple: SGLang deterministic
* Darker Purple shades: LLM-42 @2%, LLM-42 @5%, LLM-42 @10%, LLM-42 @20%, LLM-42 @50%, LLM-42 @100%
* **Value Labels:** Small text labels positioned above each bar, indicating a ratio (e.g., "0.70x", "1.00x").
### Detailed Analysis
The chart consists of eight groups of bars, each corresponding to a different dataset/token length combination. Within each group, there are bars representing SGLang deterministic, SGLang non-deterministic, and six different levels of LLM-42 non-determinism.
**ArXiv:**
* SGLang deterministic: ~15000 tokens/s, ratio 0.84x
* SGLang non-deterministic: ~16000 tokens/s, ratio 1.00x
* LLM-42 @2%: ~14000 tokens/s, ratio 0.70x
* LLM-42 @5%: ~14000 tokens/s, ratio 0.78x
* LLM-42 @10%: ~14000 tokens/s, ratio 0.84x
* LLM-42 @20%: ~14000 tokens/s, ratio 0.84x
* LLM-42 @50%: ~14000 tokens/s, ratio 0.84x
* LLM-42 @100%: ~14000 tokens/s, ratio 0.84x
**ShareGPT:**
* SGLang deterministic: ~8000 tokens/s, ratio 0.56x
* SGLang non-deterministic: ~11000 tokens/s, ratio 0.64x
* LLM-42 @2%: ~9000 tokens/s, ratio 0.66x
* LLM-42 @5%: ~9000 tokens/s, ratio 0.72x
* LLM-42 @10%: ~9000 tokens/s, ratio 0.72x
* LLM-42 @20%: ~9000 tokens/s, ratio 0.72x
* LLM-42 @50%: ~9000 tokens/s, ratio 0.72x
* LLM-42 @100%: ~9000 tokens/s, ratio 0.72x
**in=1024 out=256:**
* SGLang deterministic: ~16000 tokens/s, ratio 0.89x
* SGLang non-deterministic: ~17000 tokens/s, ratio 0.90x
* LLM-42 @2%: ~15000 tokens/s, ratio 0.86x
* LLM-42 @5%: ~15000 tokens/s, ratio 0.86x
* LLM-42 @10%: ~15000 tokens/s, ratio 0.86x
* LLM-42 @20%: ~15000 tokens/s, ratio 0.86x
* LLM-42 @50%: ~15000 tokens/s, ratio 0.86x
* LLM-42 @100%: ~15000 tokens/s, ratio 0.86x
**in=1024 out=512:**
* SGLang deterministic: ~13000 tokens/s, ratio 0.73x
* SGLang non-deterministic: ~14000 tokens/s, ratio 0.79x
* LLM-42 @2%: ~13000 tokens/s, ratio 0.66x
* LLM-42 @5%: ~13000 tokens/s, ratio 0.76x
* LLM-42 @10%: ~13000 tokens/s, ratio 0.76x
* LLM-42 @20%: ~13000 tokens/s, ratio 0.76x
* LLM-42 @50%: ~13000 tokens/s, ratio 0.76x
* LLM-42 @100%: ~13000 tokens/s, ratio 0.76x
**in=2048 out=256:**
* SGLang deterministic: ~16000 tokens/s, ratio 0.97x
* SGLang non-deterministic: ~17000 tokens/s, ratio 1.00x
* LLM-42 @2%: ~15000 tokens/s, ratio 0.92x
* LLM-42 @5%: ~15000 tokens/s, ratio 0.92x
* LLM-42 @10%: ~15000 tokens/s, ratio 0.92x
* LLM-42 @20%: ~15000 tokens/s, ratio 0.92x
* LLM-42 @50%: ~15000 tokens/s, ratio 0.92x
* LLM-42 @100%: ~15000 tokens/s, ratio 0.92x
**in=2048 out=512:**
* SGLang deterministic: ~13000 tokens/s, ratio 0.76x
* SGLang non-deterministic: ~14000 tokens/s, ratio 0.85x
* LLM-42 @2%: ~13000 tokens/s, ratio 0.74x
* LLM-42 @5%: ~13000 tokens/s, ratio 0.74x
* LLM-42 @10%: ~13000 tokens/s, ratio 0.74x
* LLM-42 @20%: ~13000 tokens/s, ratio 0.74x
* LLM-42 @50%: ~13000 tokens/s, ratio 0.74x
* LLM-42 @100%: ~13000 tokens/s, ratio 0.74x
**in=4096 out=256:**
* SGLang deterministic: ~13000 tokens/s, ratio 0.85x
* SGLang non-deterministic: ~14000 tokens/s, ratio 0.99x
* LLM-42 @2%: ~13000 tokens/s, ratio 0.85x
* LLM-42 @5%: ~13000 tokens/s, ratio 0.85x
* LLM-42 @10%: ~13000 tokens/s, ratio 0.85x
* LLM-42 @20%: ~13000 tokens/s, ratio 0.85x
* LLM-42 @50%: ~13000 tokens/s, ratio 0.85x
* LLM-42 @100%: ~13000 tokens/s, ratio 0.85x
**in=4096 out=512:**
* SGLang deterministic: ~9000 tokens/s, ratio 0.64x
* SGLang non-deterministic: ~11000 tokens/s, ratio 0.72x
* LLM-42 @2%: ~9000 tokens/s, ratio 0.64x
* LLM-42 @5%: ~9000 tokens/s, ratio 0.64x
* LLM-42 @10%: ~9000 tokens/s, ratio 0.64x
* LLM-42 @20%: ~9000 tokens/s, ratio 0.64x
* LLM-42 @50%: ~9000 tokens/s, ratio 0.64x
* LLM-42 @100%: ~9000 tokens/s, ratio 0.64x
### Key Observations
* SGLang non-deterministic consistently outperforms SGLang deterministic across all datasets/token lengths.
* LLM-42's throughput is relatively stable across different levels of non-determinism for each dataset/token length combination.
* The throughput of LLM-42 is generally lower than that of SGLang, especially the non-deterministic version.
* The highest throughput is achieved with SGLang non-deterministic on the ArXiv dataset.
* The lowest throughput is observed with LLM-42 on the in=4096 out=512 dataset.
### Interpretation
The data suggests that non-determinism in SGLang improves throughput, potentially by allowing for more parallelization or exploration of different solution paths. The lack of significant variation in LLM-42's throughput with changing non-determinism levels indicates that the model may not be effectively utilizing the increased randomness. The consistent performance of LLM-42 across different non-determinism levels could also suggest that other factors are limiting its throughput. The differences in throughput between datasets likely reflect the complexity of the data and the model's ability to process it efficiently. The ratios provided allow for a direct comparison of performance relative to an unspecified baseline, highlighting the relative gains or losses associated with each configuration. The chart provides valuable insights into the trade-offs between determinism, throughput, and model performance for different language models and datasets.
DECODING INTELLIGENCE...