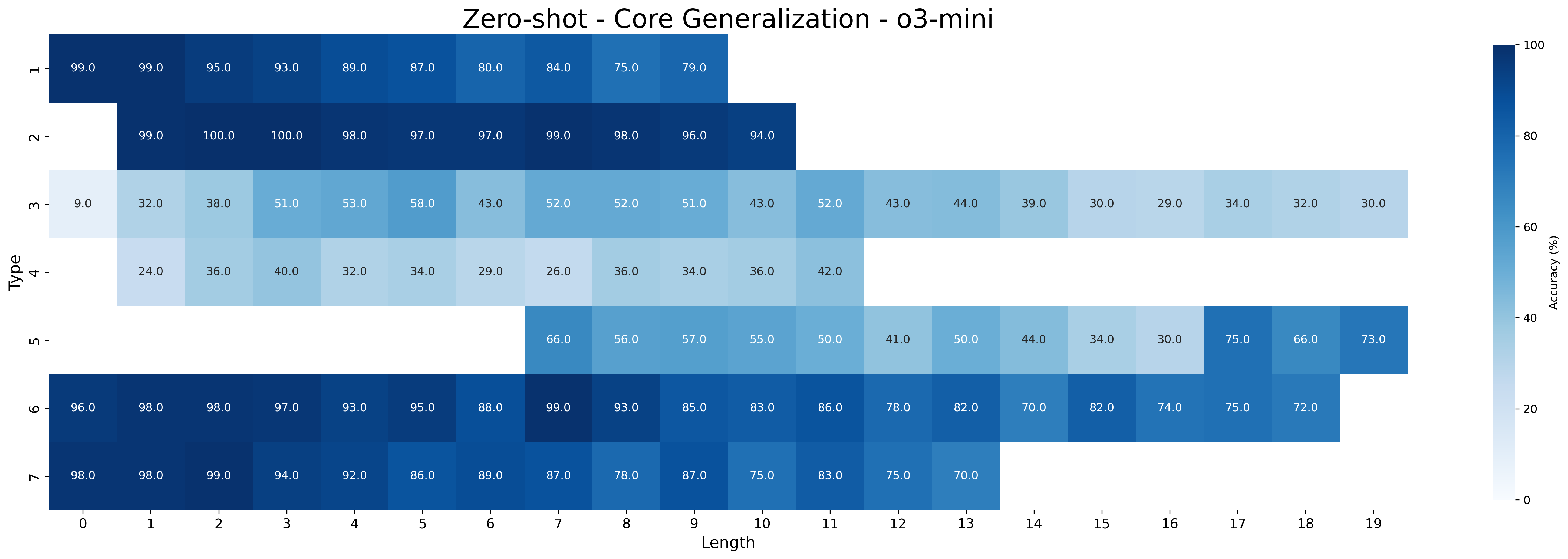
## Heatmap: Zero-shot - Core Generalization - o3-mini
### Overview
This image presents a heatmap visualizing the accuracy of a model ("o3-mini") in a zero-shot core generalization task. The heatmap displays accuracy percentages based on two dimensions: "Type" and "Length". The "Type" dimension represents different categories (h-, 2-, m-, 4-, un-, o-, >), while "Length" represents the length of the input, ranging from 0 to 19. The color intensity of each cell corresponds to the accuracy percentage, with darker blues indicating higher accuracy and lighter shades indicating lower accuracy.
### Components/Axes
* **Title:** "Zero-shot - Core Generalization - o3-mini" (Top-center)
* **X-axis:** "Length" - ranging from 0 to 19, with integer values. (Bottom)
* **Y-axis:** "Type" - with the following categories:
* h-
* 2-
* m-
* 4-
* un-
* o-
* >- (Bottom-left)
* **Color Scale/Legend:** A vertical color bar on the right side of the heatmap, representing accuracy percentages from 0% to 100%. (Right)
### Detailed Analysis
The heatmap is a 7x20 grid. Each cell represents the accuracy for a specific combination of "Type" and "Length". The values are approximate, based on visual estimation.
* **h- Type:**
* Length 0: ~99.0%
* Length 1: ~99.0%
* Length 2: ~95.0%
* Length 3: ~89.0%
* Length 4: ~87.0%
* Length 5: ~80.0%
* Length 6: ~75.0%
* Length 7: ~79.0%
* **2- Type:**
* Length 0: ~99.3%
* Length 1: ~100.0%
* Length 2: ~98.0%
* Length 3: ~97.0%
* Length 4: ~98.0%
* Length 5: ~96.0%
* Length 6: ~94.0%
* **m- Type:**
* Length 0: ~32.0%
* Length 1: ~38.0%
* Length 2: ~51.0%
* Length 3: ~58.0%
* Length 4: ~43.0%
* Length 5: ~52.0%
* Length 6: ~41.0%
* Length 7: ~52.0%
* **4- Type:**
* Length 0: ~24.0%
* Length 1: ~36.0%
* Length 2: ~40.0%
* Length 3: ~34.0%
* Length 4: ~26.0%
* Length 5: ~36.0%
* Length 6: ~36.0%
* Length 7: ~42.0%
* **un- Type:**
* Length 6: ~66.0%
* Length 7: ~56.0%
* Length 8: ~57.0%
* Length 9: ~50.0%
* Length 10: ~41.0%
* Length 11: ~44.0%
* Length 12: ~30.0%
* Length 13: ~75.0%
* Length 14: ~66.0%
* Length 15: ~73.0%
* **o- Type:**
* Length 0: ~96.0%
* Length 1: ~98.0%
* Length 2: ~97.0%
* Length 3: ~95.0%
* Length 4: ~88.0%
* Length 5: ~89.0%
* Length 6: ~83.0%
* Length 7: ~85.0%
* **>- Type:**
* Length 0: ~98.0%
* Length 1: ~94.0%
* Length 2: ~92.0%
* Length 3: ~86.0%
* Length 4: ~87.0%
* Length 5: ~78.0%
* Length 6: ~83.0%
* Length 7: ~75.0%
**Trends:**
* For "h-" and "2-" types, accuracy is generally high (above 80%) and tends to decrease slightly as length increases.
* "m-" and "4-" types exhibit significantly lower accuracy, generally below 60%, with some fluctuations.
* "un-" type shows a complex pattern, with accuracy initially decreasing and then increasing again at higher lengths.
* "o-" and ">-" types show high accuracy, similar to "h-" and "2-", but with more noticeable decreases at higher lengths.
### Key Observations
* The "h-" and "2-" types consistently demonstrate the highest accuracy across all lengths.
* The "m-" and "4-" types have the lowest accuracy, indicating the model struggles with these categories.
* The "un-" type shows a non-monotonic relationship between length and accuracy, suggesting a more complex interaction.
* Accuracy generally decreases as the length of the input increases, but the rate of decrease varies significantly between types.
### Interpretation
The heatmap reveals that the "o3-mini" model performs well on certain types of inputs ("h-" and "2-") in a zero-shot setting, achieving high accuracy even with increasing length. However, it struggles with other types ("m-" and "4-"), indicating potential biases or limitations in its generalization capabilities. The varying trends across different types suggest that the model's performance is sensitive to the specific characteristics of the input data. The non-monotonic behavior of the "un-" type warrants further investigation to understand the underlying factors influencing its accuracy.
This data suggests that the model is not universally capable of generalizing to all core types without any prior training. The performance differences between types highlight the importance of considering the diversity of input data when evaluating and deploying zero-shot learning models. The decrease in accuracy with increasing length could be due to the model's limited capacity to process longer sequences or the increased difficulty of maintaining context over longer inputs.