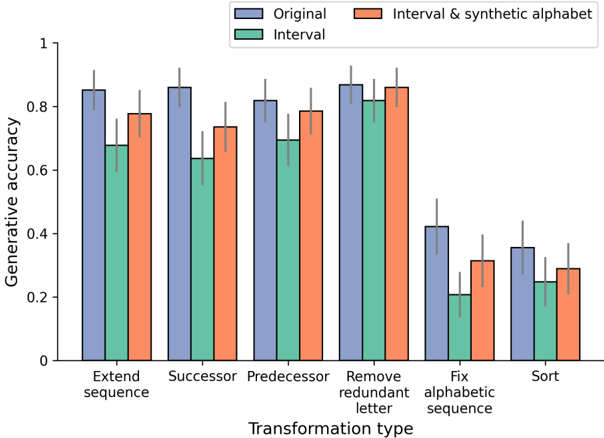
## Bar Chart: Generative Accuracy Across Transformation Types
### Overview
The chart compares generative accuracy (y-axis: 0–1) across six transformation types (x-axis) for three methods: Original, Interval & synthetic alphabet, and Interval. Error bars indicate uncertainty in measurements.
### Components/Axes
- **X-axis (Transformation type)**:
Extend sequence, Successor, Predecessor, Remove redundant letter, Fix alphabetic sequence, Sort
- **Y-axis (Generative accuracy)**:
Scale from 0 to 1, labeled "Generative accuracy"
- **Legend**:
- Blue: Original
- Orange: Interval & synthetic alphabet
- Green: Interval
Positioned in the top-right corner.
### Detailed Analysis
1. **Extend sequence**:
- Original: ~0.85 (±0.05)
- Interval & synthetic alphabet: ~0.78 (±0.04)
- Interval: ~0.68 (±0.06)
2. **Successor**:
- Original: ~0.87 (±0.04)
- Interval & synthetic alphabet: ~0.74 (±0.05)
- Interval: ~0.64 (±0.07)
3. **Predecessor**:
- Original: ~0.82 (±0.03)
- Interval & synthetic alphabet: ~0.79 (±0.04)
- Interval: ~0.69 (±0.05)
4. **Remove redundant letter**:
- Original: ~0.88 (±0.03)
- Interval & synthetic alphabet: ~0.85 (±0.04)
- Interval: ~0.82 (±0.03)
5. **Fix alphabetic sequence**:
- Original: ~0.42 (±0.06)
- Interval & synthetic alphabet: ~0.31 (±0.05)
- Interval: ~0.21 (±0.04)
6. **Sort**:
- Original: ~0.36 (±0.05)
- Interval & synthetic alphabet: ~0.29 (±0.04)
- Interval: ~0.25 (±0.03)
### Key Observations
- **Original** consistently outperforms other methods across all transformations, with the highest accuracy in "Remove redundant letter" (~0.88).
- **Interval & synthetic alphabet** shows moderate performance, with a notable drop in "Fix alphabetic sequence" (~0.31) and "Sort" (~0.29).
- **Interval** has the lowest accuracy, particularly in "Fix alphabetic sequence" (~0.21) and "Sort" (~0.25).
- Error bars suggest greater variability in Original and Interval & synthetic alphabet compared to Interval.
### Interpretation
The data demonstrates that the **Original** method maintains the highest generative accuracy, likely due to its reliance on full data context. The **Interval & synthetic alphabet** method bridges the gap between Original and Interval, suggesting synthetic data augmentation improves performance over pure interval-based approaches. However, all methods struggle with complex transformations like "Fix alphabetic sequence" and "Sort," where accuracy drops sharply. The **Interval** method’s lower accuracy may stem from insufficient data granularity or inability to model dependencies in altered sequences. The error bars highlight that while Original is most accurate, its results are less consistent than Interval-based methods.