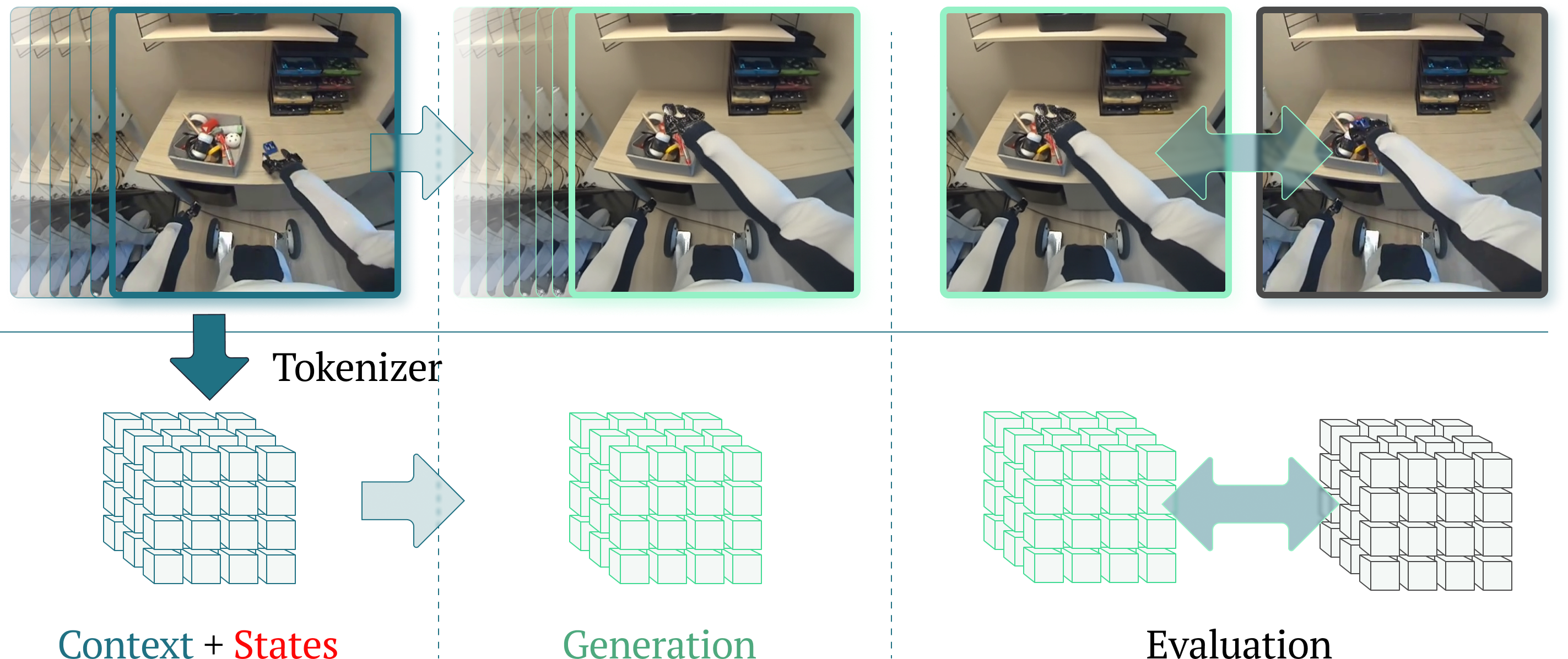
\n
## Diagram: Robotic Manipulation Pipeline
### Overview
The image depicts a diagram illustrating a pipeline for robotic manipulation, likely within a reinforcement learning or imitation learning framework. The pipeline takes visual input from a robotic arm interacting with objects in a scene, processes it through a "Tokenizer", and then proceeds through stages of "Generation" and "Evaluation". The visual input is shown as a series of four images capturing different stages of a robotic arm grasping a toy.
### Components/Axes
The diagram consists of four main sections arranged horizontally:
1. **Visual Input:** Four images showing a robotic arm interacting with objects on a desk.
2. **Tokenizer:** A block labeled "Tokenizer" with an arrow indicating transformation of the visual input.
3. **Generation:** A 3D cube representation labeled "Generation".
4. **Evaluation:** Two 3D cube representations labeled "Evaluation" with a bidirectional arrow between them.
Below these sections are labels: "Context + States", "Generation", and "Evaluation". The visual input images are connected to the "Tokenizer" by light blue, semi-transparent overlays highlighting the region of interest in each image.
### Detailed Analysis or Content Details
The four images in the "Visual Input" section show a robotic arm with a gripper attempting to grasp a red and yellow toy. The images progress from the arm approaching the toy to the arm successfully grasping it.
* **Image 1:** The robotic arm is extending towards the toy.
* **Image 2:** The gripper is closing around the toy.
* **Image 3:** The gripper is fully closed around the toy.
* **Image 4:** The arm is lifting the toy.
The "Tokenizer" block suggests a process of converting the visual input into a tokenized representation. The 3D cubes in "Generation" and "Evaluation" likely represent latent spaces or state representations. The bidirectional arrow between the two "Evaluation" cubes suggests an iterative process or feedback loop.
The "Context + States" label is positioned below the "Tokenizer" and the first "Generation" cube.
### Key Observations
The diagram highlights the transformation of raw visual data into a structured representation suitable for robotic control. The use of 3D cubes suggests a learned representation, potentially a latent space learned through deep learning. The iterative "Evaluation" stage indicates a process of refining the robotic action based on feedback.
### Interpretation
This diagram illustrates a common architecture for robotic learning, particularly in areas like reinforcement learning or imitation learning. The "Tokenizer" likely represents a convolutional neural network (CNN) or a vision transformer (ViT) that extracts features from the images. These features are then used to create a state representation ("Context + States") that is fed into a policy or value function for "Generation" of actions. The "Evaluation" stage likely involves assessing the quality of the generated actions and providing feedback to improve the policy. The iterative nature of the "Evaluation" stage suggests a learning loop where the robot continuously improves its performance through trial and error. The highlighted regions in the images suggest that the system focuses on the interaction between the gripper and the object, indicating that this is the key area of interest for the learning process. The diagram doesn't provide specific numerical data, but it conveys a clear conceptual framework for robotic manipulation learning.