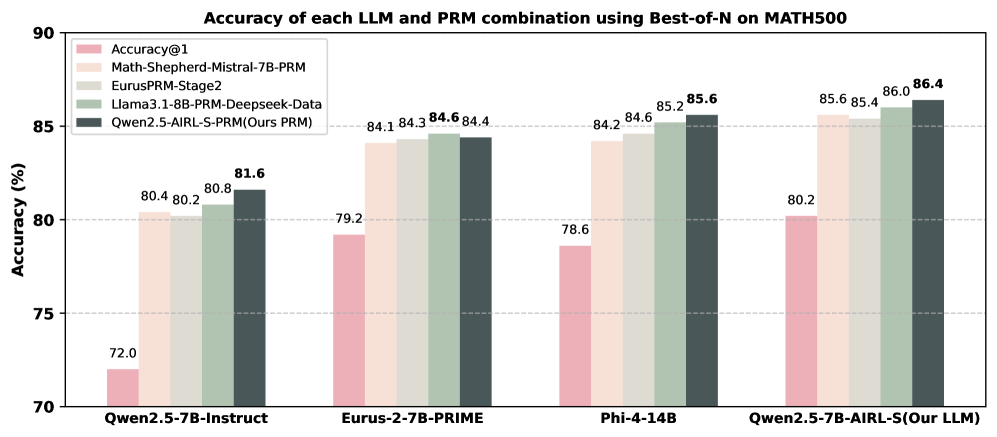
## Bar Chart: Accuracy of each LLM and PRM combination using Best-of-N on MATH500
### Overview
The chart compares the accuracy of different combinations of Large Language Models (LLMs) and Prompt Retrieval Models (PRMs) on the MATH500 benchmark. It uses grouped bar charts to visualize performance across four LLM configurations, with five distinct PRM combinations represented by color-coded bars. The y-axis measures accuracy in percentage, while the x-axis lists the LLM-PRM pairs.
### Components/Axes
- **X-axis (Categories)**:
- Qwen2.5-7B-Instruct
- Eurus-2-7B-PRIME
- Phi-4-14B
- Qwen2.5-7B-AIRL-S (Our LLM)
- **Y-axis (Values)**: Accuracy (%) ranging from 70 to 90.
- **Legend**:
- **Accuracy@1** (pink)
- **Math-Shepherd-Mistral-7B-PRM** (light orange)
- **EurusPRM-Stage2** (light green)
- **Llama3.1-8B-PRM-Deepseek-Data** (medium green)
- **Qwen2.5-AIRL-S-PRM (Ours PRM)** (dark blue)
### Detailed Analysis
- **Qwen2.5-7B-Instruct**:
- Accuracy@1: 72.0%
- Math-Shepherd-Mistral-7B-PRM: 80.4%
- EurusPRM-Stage2: 80.8%
- Llama3.1-8B-PRM-Deepseek-Data: 81.6%
- Qwen2.5-AIRL-S-PRM: 81.6%
- **Eurus-2-7B-PRIME**:
- Accuracy@1: 79.2%
- Math-Shepherd-Mistral-7B-PRM: 84.1%
- EurusPRM-Stage2: 84.3%
- Llama3.1-8B-PRM-Deepseek-Data: 84.6%
- Qwen2.5-AIRL-S-PRM: 84.4%
- **Phi-4-14B**:
- Accuracy@1: 78.6%
- Math-Shepherd-Mistral-7B-PRM: 84.2%
- EurusPRM-Stage2: 84.3%
- Llama3.1-8B-PRM-Deepseek-Data: 85.2%
- Qwen2.5-AIRL-S-PRM: 85.6%
- **Qwen2.5-7B-AIRL-S (Our LLM)**:
- Accuracy@1: 80.2%
- Math-Shepherd-Mistral-7B-PRM: 85.6%
- EurusPRM-Stage2: 85.4%
- Llama3.1-8B-PRM-Deepseek-Data: 86.0%
- Qwen2.5-AIRL-S-PRM: 86.4%
### Key Observations
1. **Qwen2.5-AIRL-S-PRM (dark blue)** consistently achieves the highest accuracy across all LLM configurations, with values ranging from 81.6% to 86.4%.
2. **Accuracy@1 (pink)** is the lowest-performing metric in every group, indicating baseline performance without PRM enhancements.
3. **Math-Shepherd-Mistral-7B-PRM (light orange)** and **EurusPRM-Stage2 (light green)** show moderate improvements over Accuracy@1 but lag behind Qwen2.5-AIRL-S-PRM.
4. **Llama3.1-8B-PRM-Deepseek-Data (medium green)** performs slightly better than Math-Shepherd-Mistral-7B-PRM in most cases but remains below Qwen2.5-AIRL-S-PRM.
### Interpretation
The data demonstrates that the **Qwen2.5-AIRL-S-PRM** combination outperforms all other PRM configurations across all tested LLMs, suggesting it is the most effective pairing for the MATH500 benchmark. The **Accuracy@1** metric serves as a baseline, while the other PRMs represent incremental improvements. Notably, the Qwen2.5-AIRL-S-PRM achieves a 4.4% higher accuracy than the next-best PRM (Llama3.1-8B-PRM-Deepseek-Data) in the Qwen2.5-7B-AIRL-S group, highlighting its superior performance. This trend underscores the importance of PRM design in enhancing LLM accuracy for mathematical reasoning tasks.