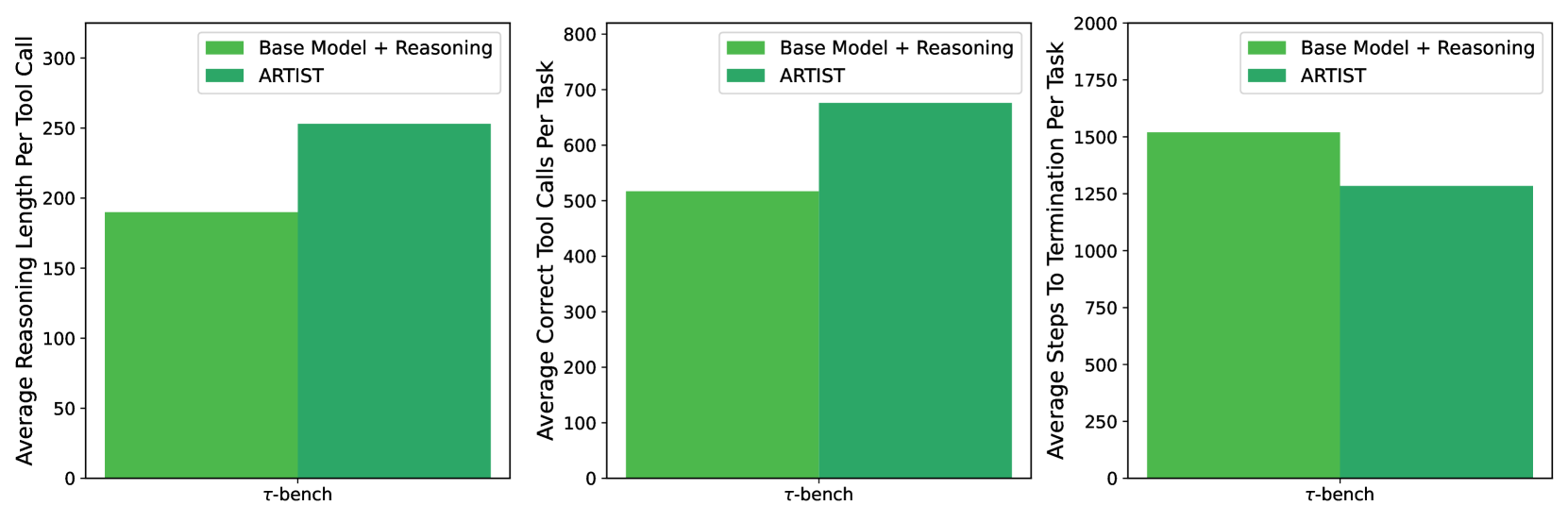
## Bar Charts: Performance Comparison of Two Models on τ-bench
### Overview
The image contains three separate bar charts arranged horizontally. Each chart compares the performance of two models—"Base Model + Reasoning" and "ARTIST"—on a single benchmark called "τ-bench". The charts measure three distinct performance metrics. The overall visual presentation uses a consistent color scheme and layout.
### Components/Axes
* **Common Elements Across All Charts:**
* **X-Axis Label:** "τ-bench" (centered below each chart).
* **Legend:** Located in the top-right corner of each chart's plotting area. It contains two entries:
* A light green square labeled "Base Model + Reasoning".
* A dark green square labeled "ARTIST".
* **Chart Type:** Vertical bar chart.
* **Data Series:** Two bars per chart, one for each model.
* **Chart 1 (Left):**
* **Y-Axis Title:** "Average Reasoning Length Per Tool Call".
* **Y-Axis Scale:** Linear scale from 0 to 300, with major tick marks at intervals of 50 (0, 50, 100, 150, 200, 250, 300).
* **Chart 2 (Center):**
* **Y-Axis Title:** "Average Correct Tool Calls Per Task".
* **Y-Axis Scale:** Linear scale from 0 to 800, with major tick marks at intervals of 100 (0, 100, 200, 300, 400, 500, 600, 700, 800).
* **Chart 3 (Right):**
* **Y-Axis Title:** "Average Steps To Termination Per Task".
* **Y-Axis Scale:** Linear scale from 0 to 2000, with major tick marks at intervals of 250 (0, 250, 500, 750, 1000, 1250, 1500, 1750, 2000).
### Detailed Analysis
**Chart 1: Average Reasoning Length Per Tool Call**
* **Visual Trend:** The bar for "ARTIST" (dark green) is visibly taller than the bar for "Base Model + Reasoning" (light green).
* **Data Points (Approximate):**
* Base Model + Reasoning: ~190
* ARTIST: ~250
* **Interpretation:** On the τ-bench benchmark, the ARTIST model generates longer reasoning sequences per tool call compared to the base model with reasoning.
**Chart 2: Average Correct Tool Calls Per Task**
* **Visual Trend:** The bar for "ARTIST" (dark green) is taller than the bar for "Base Model + Reasoning" (light green).
* **Data Points (Approximate):**
* Base Model + Reasoning: ~515
* ARTIST: ~675
* **Interpretation:** The ARTIST model executes a higher number of correct tool calls per task on τ-bench.
**Chart 3: Average Steps To Termination Per Task**
* **Visual Trend:** The bar for "ARTIST" (dark green) is shorter than the bar for "Base Model + Reasoning" (light green).
* **Data Points (Approximate):**
* Base Model + Reasoning: ~1520
* ARTIST: ~1280
* **Interpretation:** The ARTIST model requires fewer average steps to reach task termination on τ-bench.
### Key Observations
1. **Consistent Superiority:** The ARTIST model outperforms the "Base Model + Reasoning" on all three presented metrics for the τ-bench benchmark.
2. **Metric Relationships:** There is an inverse relationship between the trends in Chart 1 and Chart 3. While ARTIST has a *longer* reasoning length per call (Chart 1), it achieves task completion in *fewer* total steps (Chart 3). This suggests its reasoning, though more verbose per step, is more efficient overall.
3. **Magnitude of Difference:** The relative performance gap is most pronounced in the "Average Correct Tool Calls Per Task" metric (Chart 2), where ARTIST shows a substantial increase (~31% higher than the base model).
### Interpretation
The data suggests that the ARTIST model represents a significant improvement over a base model augmented with reasoning capabilities for the τ-bench benchmark. The key takeaway is not just that ARTIST performs better, but *how* it performs better:
* **Quality over Brevity:** ARTIST invests more computational effort (longer reasoning) into each individual tool call. This investment appears to pay off by making each call more effective.
* **Increased Efficacy:** The higher number of correct tool calls per task indicates that ARTIST's actions are more accurate or appropriate for the task at hand.
* **Improved Efficiency:** Despite the longer reasoning per step, the overall process is more streamlined, requiring fewer total steps to complete a task. This implies that the improved quality of each step reduces backtracking, error correction, or unnecessary actions.
In summary, the charts demonstrate that ARTIST is not merely scaling up activity (more calls, more steps) but is enhancing the *quality and efficiency* of its problem-solving process on this benchmark. The "Base Model + Reasoning" appears to be less precise, requiring more total steps and making fewer correct calls, even though its individual reasoning steps are shorter.