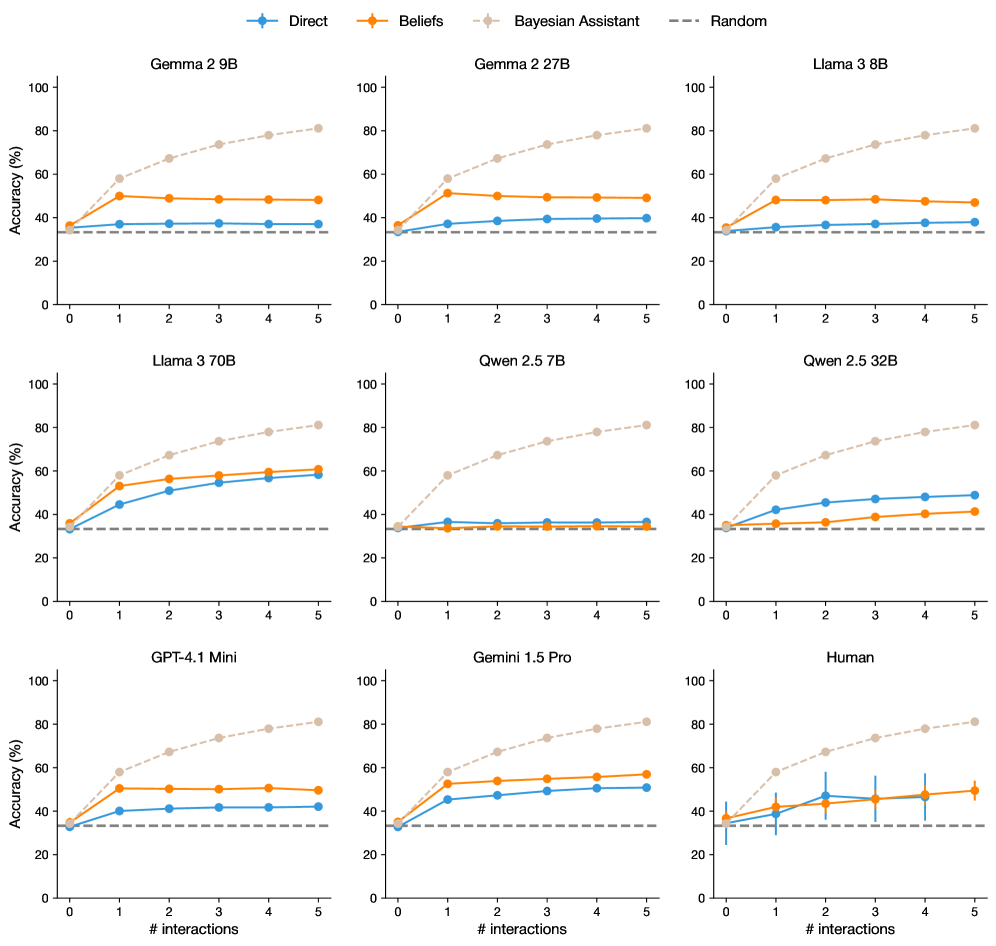
## Chart Type: Small Multiples Line Chart
### Overview
The image presents a small multiples line chart comparing the accuracy of different language models ("Direct", "Beliefs", and "Bayesian Assistant") across varying numbers of interactions (0 to 5). A "Random" baseline is also shown. Each subplot represents a different model (e.g., Gemma 2 9B, Llama 3 70B, Human).
### Components/Axes
* **X-axis:** "# interactions" ranging from 0 to 5.
* **Y-axis:** "Accuracy (%)" ranging from 0 to 100.
* **Legend (top):**
* Blue line: "Direct"
* Orange line: "Beliefs"
* Light Brown dashed line: "Bayesian Assistant"
* Gray dashed line: "Random"
* **Subplot Titles:** Each subplot is titled with the name of the language model being evaluated (e.g., "Gemma 2 9B", "Llama 3 8B", "Human").
### Detailed Analysis
**General Observations:**
* All subplots share the same x and y axis scales.
* The "Random" baseline is consistently a horizontal dashed line at approximately 33% accuracy across all subplots.
* The "Bayesian Assistant" generally shows the highest accuracy after several interactions, with an upward sloping trend.
* "Direct" and "Beliefs" methods show varying performance depending on the model, sometimes remaining relatively flat.
**Specific Model Analysis:**
* **Gemma 2 9B:**
* "Direct" (blue): Stays relatively constant around 40% accuracy.
* "Beliefs" (orange): Stays relatively constant around 50% accuracy.
* "Bayesian Assistant" (light brown dashed): Increases from approximately 40% to 80% accuracy.
* "Random" (gray dashed): Approximately 33% accuracy.
* **Gemma 2 27B:**
* "Direct" (blue): Stays relatively constant around 40% accuracy.
* "Beliefs" (orange): Stays relatively constant around 50% accuracy.
* "Bayesian Assistant" (light brown dashed): Increases from approximately 40% to 80% accuracy.
* "Random" (gray dashed): Approximately 33% accuracy.
* **Llama 3 8B:**
* "Direct" (blue): Stays relatively constant around 40% accuracy.
* "Beliefs" (orange): Stays relatively constant around 50% accuracy.
* "Bayesian Assistant" (light brown dashed): Increases from approximately 40% to 80% accuracy.
* "Random" (gray dashed): Approximately 33% accuracy.
* **Llama 3 70B:**
* "Direct" (blue): Increases from approximately 35% to 60% accuracy.
* "Beliefs" (orange): Increases from approximately 40% to 65% accuracy.
* "Bayesian Assistant" (light brown dashed): Increases from approximately 40% to 80% accuracy.
* "Random" (gray dashed): Approximately 33% accuracy.
* **Qwen 2.5 7B:**
* "Direct" (blue): Stays relatively constant around 35% accuracy.
* "Beliefs" (orange): Stays relatively constant around 35% accuracy.
* "Bayesian Assistant" (light brown dashed): Increases from approximately 35% to 80% accuracy.
* "Random" (gray dashed): Approximately 33% accuracy.
* **Qwen 2.5 32B:**
* "Direct" (blue): Increases from approximately 35% to 50% accuracy.
* "Beliefs" (orange): Increases from approximately 35% to 40% accuracy.
* "Bayesian Assistant" (light brown dashed): Increases from approximately 35% to 80% accuracy.
* "Random" (gray dashed): Approximately 33% accuracy.
* **GPT-4.1 Mini:**
* "Direct" (blue): Increases from approximately 35% to 50% accuracy.
* "Beliefs" (orange): Increases from approximately 35% to 55% accuracy.
* "Bayesian Assistant" (light brown dashed): Increases from approximately 35% to 80% accuracy.
* "Random" (gray dashed): Approximately 33% accuracy.
* **Gemini 1.5 Pro:**
* "Direct" (blue): Increases from approximately 35% to 50% accuracy.
* "Beliefs" (orange): Increases from approximately 35% to 60% accuracy.
* "Bayesian Assistant" (light brown dashed): Increases from approximately 35% to 80% accuracy.
* "Random" (gray dashed): Approximately 33% accuracy.
* **Human:**
* "Direct" (blue): Starts at approximately 35% and fluctuates between 40% and 50% accuracy, with error bars indicating variability.
* "Beliefs" (orange): Starts at approximately 40% and fluctuates between 45% and 55% accuracy, with error bars indicating variability.
* "Bayesian Assistant" (light brown dashed): Increases from approximately 35% to 80% accuracy.
* "Random" (gray dashed): Approximately 33% accuracy.
### Key Observations
* The "Bayesian Assistant" method consistently outperforms "Direct" and "Beliefs" methods across all language models as the number of interactions increases.
* The "Random" baseline provides a consistent lower bound for performance.
* The performance of "Direct" and "Beliefs" methods varies depending on the specific language model.
* Human performance is relatively stable after the initial interaction, with noticeable variability (error bars).
### Interpretation
The data suggests that the "Bayesian Assistant" method is highly effective in improving the accuracy of language models through iterative interactions. This indicates that incorporating Bayesian principles into the interaction process can significantly enhance model performance. The consistent outperformance across different models suggests the robustness of this approach. The relatively flat performance of "Direct" and "Beliefs" in some models indicates that these methods may not be as effective in leveraging interactions for accuracy improvement. The human performance, while showing improvement over the random baseline, exhibits variability, suggesting the inherent complexity and subjectivity in human evaluation.