TECHNICAL ASSET FINGERPRINT
22d7ec84e8ae462ec5115695
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemma-3-27b-it-free VERSION 1
RUNTIME: google-free/gemma-3-27b-it
INTEL_VERIFIED
\n
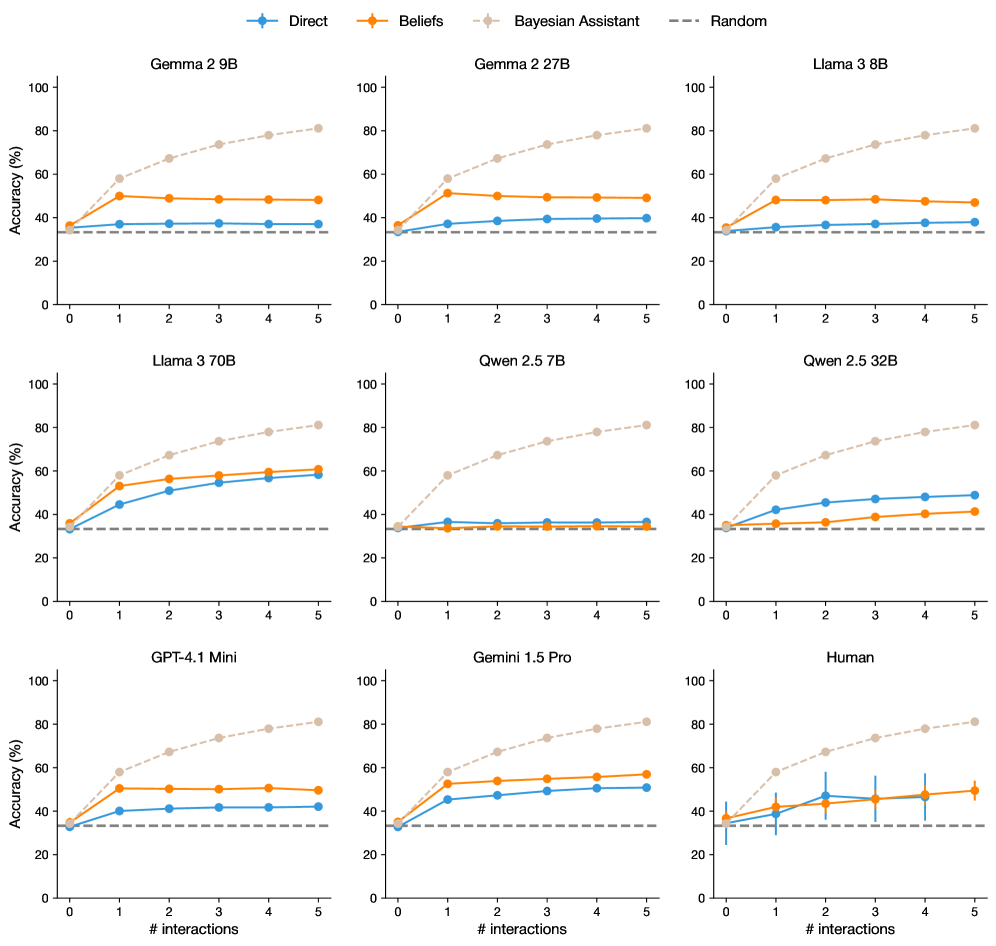
## Charts: Accuracy vs. Interactions for Various Models
### Overview
The image presents a 3x3 grid of line charts, each comparing the accuracy of different language models (Gemma 2.9B, Gemma 2.27B, Llama 3.8B, Llama 3.70B, Qwen 2.5 7B, Qwen 2.5 32B, GPT-4.1 Mini, Gemini 1.5 Pro, and Human) across a range of interaction numbers (1 to 5). Accuracy is measured in percentage (%). Each chart displays four data series representing different prompting strategies: "Direct", "Beliefs", "Bayesian Assistant", and "Random". Error bars are present on each data point, indicating the variance in accuracy.
### Components/Axes
* **X-axis:** "# interactions" - ranging from 0 to 5.
* **Y-axis:** "Accuracy (%)" - ranging from 0 to 100.
* **Legend:** Located at the top of the image, identifying the data series by color and label:
* Direct (Blue)
* Beliefs (Orange)
* Bayesian Assistant (Purple)
* Random (Gray dashed)
* **Charts:** Nine individual line charts, each representing a different model. The models are labeled above each chart.
### Detailed Analysis or Content Details
Here's a breakdown of each chart, with approximate values extracted from the visual representation. Note that due to the image resolution and line thickness, values are estimates with an uncertainty of ±2%.
**1. Gemma 2.9B**
* Direct: Starts at ~38%, increases to ~42% at interaction 2, then plateaus around ~40% for interactions 3-5.
* Beliefs: Starts at ~36%, remains relatively flat around ~38-40% across all interactions.
* Bayesian Assistant: Starts at ~42%, decreases to ~38% at interaction 2, then remains relatively flat around ~38-40% for interactions 3-5.
* Random: Starts at ~40%, decreases to ~36% at interaction 2, then remains relatively flat around ~36-38% for interactions 3-5.
**2. Gemma 2.27B**
* Direct: Starts at ~40%, increases to ~46% at interaction 2, then plateaus around ~44-46% for interactions 3-5.
* Beliefs: Starts at ~38%, remains relatively flat around ~40-42% across all interactions.
* Bayesian Assistant: Starts at ~42%, remains relatively flat around ~40-42% across all interactions.
* Random: Starts at ~40%, remains relatively flat around ~38-40% across all interactions.
**3. Llama 3.8B**
* Direct: Starts at ~40%, increases to ~46% at interaction 2, then plateaus around ~44-46% for interactions 3-5.
* Beliefs: Starts at ~38%, remains relatively flat around ~40-42% across all interactions.
* Bayesian Assistant: Starts at ~42%, remains relatively flat around ~40-42% across all interactions.
* Random: Starts at ~40%, decreases to ~36% at interaction 2, then remains relatively flat around ~36-38% for interactions 3-5.
**4. Llama 3.70B**
* Direct: Starts at ~22%, increases sharply to ~46% at interaction 2, then increases to ~52% at interaction 5.
* Beliefs: Starts at ~20%, increases to ~36% at interaction 2, then plateaus around ~36-40% for interactions 3-5.
* Bayesian Assistant: Starts at ~24%, increases to ~38% at interaction 2, then plateaus around ~38-40% for interactions 3-5.
* Random: Starts at ~22%, remains relatively flat around ~22-26% across all interactions.
**5. Qwen 2.5 7B**
* Direct: Starts at ~36%, increases to ~44% at interaction 2, then plateaus around ~42-44% for interactions 3-5.
* Beliefs: Starts at ~34%, remains relatively flat around ~36-38% across all interactions.
* Bayesian Assistant: Starts at ~38%, remains relatively flat around ~36-38% across all interactions.
* Random: Starts at ~36%, remains relatively flat around ~34-36% across all interactions.
**6. Qwen 2.5 32B**
* Direct: Starts at ~38%, increases to ~46% at interaction 2, then plateaus around ~44-46% for interactions 3-5.
* Beliefs: Starts at ~36%, remains relatively flat around ~38-40% across all interactions.
* Bayesian Assistant: Starts at ~40%, remains relatively flat around ~38-40% across all interactions.
* Random: Starts at ~38%, remains relatively flat around ~36-38% across all interactions.
**7. GPT-4.1 Mini**
* Direct: Starts at ~36%, remains relatively flat around ~38-40% across all interactions.
* Beliefs: Starts at ~34%, remains relatively flat around ~36-38% across all interactions.
* Bayesian Assistant: Starts at ~38%, remains relatively flat around ~36-38% across all interactions.
* Random: Starts at ~36%, remains relatively flat around ~34-36% across all interactions.
**8. Gemini 1.5 Pro**
* Direct: Starts at ~38%, remains relatively flat around ~40-42% across all interactions.
* Beliefs: Starts at ~36%, remains relatively flat around ~38-40% across all interactions.
* Bayesian Assistant: Starts at ~40%, remains relatively flat around ~38-40% across all interactions.
* Random: Starts at ~38%, remains relatively flat around ~36-38% across all interactions.
**9. Human**
* Direct: Starts at ~40%, decreases to ~36% at interaction 2, then remains relatively flat around ~36-38% for interactions 3-5.
* Beliefs: Starts at ~38%, decreases to ~34% at interaction 2, then remains relatively flat around ~34-36% for interactions 3-5.
* Bayesian Assistant: Starts at ~42%, decreases to ~38% at interaction 2, then remains relatively flat around ~36-38% for interactions 3-5.
* Random: Starts at ~40%, decreases to ~36% at interaction 2, then remains relatively flat around ~34-36% for interactions 3-5.
### Key Observations
* Llama 3.70B shows the most significant improvement in accuracy with increasing interactions, particularly when using the "Direct" prompting strategy.
* The "Random" prompting strategy consistently performs the worst across most models.
* The "Direct" and "Beliefs" prompting strategies generally yield higher accuracy than the "Random" strategy.
* The "Bayesian Assistant" strategy shows a slight decrease in accuracy with increasing interactions for some models.
* Human performance decreases with increasing interactions.
### Interpretation
The data suggests that increasing the number of interactions can improve the accuracy of some language models, particularly Llama 3.70B. The choice of prompting strategy significantly impacts performance, with the "Direct" strategy generally being more effective than the "Random" strategy. The relatively flat performance of many models across interactions suggests a saturation point where additional interactions do not lead to substantial accuracy gains. The decrease in human performance with increasing interactions is an interesting outlier, potentially indicating a cognitive fatigue effect or a change in task approach. The error bars indicate that the observed differences in accuracy may not always be statistically significant, and further investigation is needed to confirm these trends. The comparison between models highlights the varying capabilities of different architectures and training datasets. The Bayesian Assistant strategy's initial high performance followed by a plateau or slight decrease could indicate that the model benefits from initial contextualization but doesn't effectively integrate further information.
DECODING INTELLIGENCE...