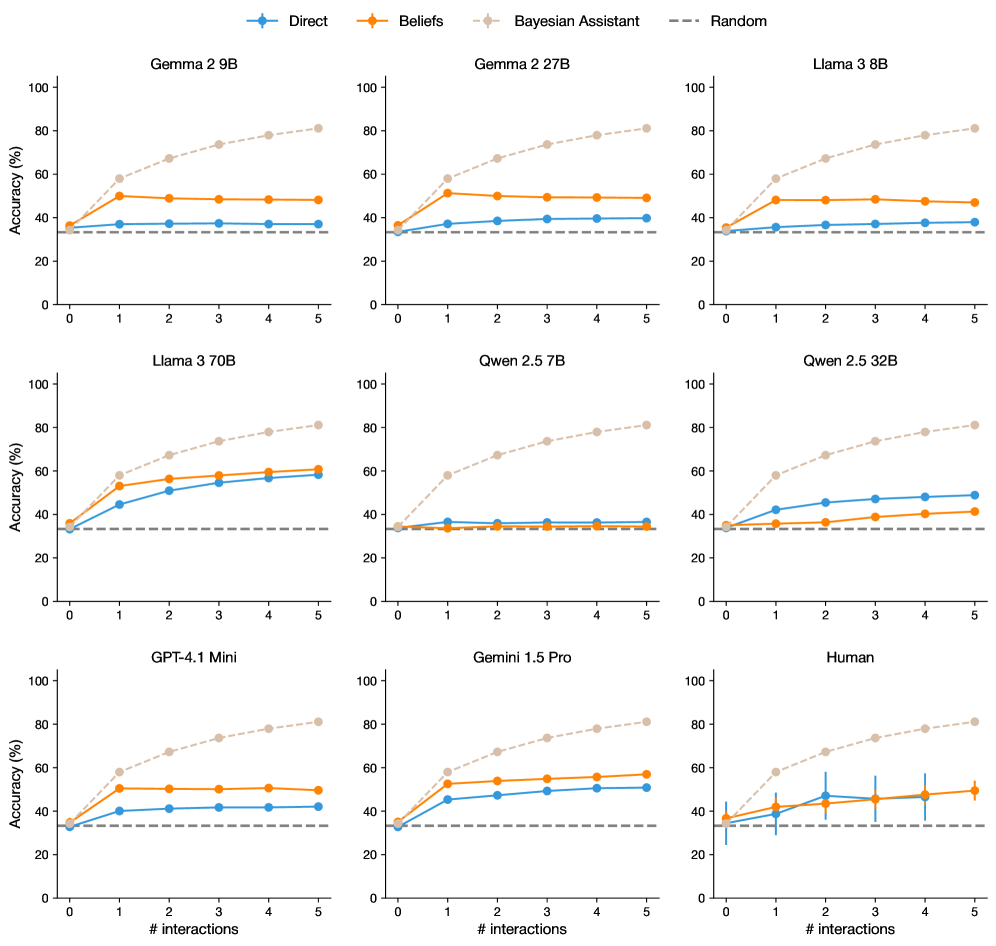
## Line Chart Grid: Model Performance Across Interaction Counts
### Overview
The image displays a 3x3 grid of line charts comparing the accuracy performance of different AI models (Gemma 2 9B, Gemma 2 27B, Llama 3 8B, Llama 3 70B, Quen 2.5 7B, Quen 2.5 32B, GPT-4.1 Mini, Gemini 1.5 Pro, and Human) across 5 interaction counts (0-5). Each chart tracks three performance metrics: Direct, Beliefs, and Bayesian Assistant, against a Random baseline. All charts share identical axes and legend conventions.
### Components/Axes
- **X-axis**: "# interactions" (0-5, integer scale)
- **Y-axis**: "Accuracy (%)" (0-100, linear scale)
- **Legend**:
- Blue circles: Direct
- Orange squares: Beliefs
- Gray diamonds: Bayesian Assistant
- Dashed gray line: Random baseline
- **Chart Titles**: Model names (e.g., "Gemma 2 9B", "Human") positioned at top of each subplot
### Detailed Analysis
1. **Gemma 2 9B**
- Direct: 35% → 55% (steady increase)
- Beliefs: 40% → 50% (moderate growth)
- Bayesian Assistant: 35% → 80% (sharp improvement)
- Random: 30% (flat)
2. **Gemma 2 27B**
- Direct: 30% → 45% (consistent rise)
- Beliefs: 40% → 50% (flat after interaction 3)
- Bayesian Assistant: 35% → 80% (linear growth)
- Random: 30% (flat)
3. **Llama 3 8B**
- Direct: 35% → 45% (slow climb)
- Beliefs: 40% → 45% (minimal improvement)
- Bayesian Assistant: 35% → 80% (rapid ascent)
- Random: 30% (flat)
4. **Llama 3 70B**
- Direct: 30% → 55% (steep increase)
- Beliefs: 40% → 60% (moderate growth)
- Bayesian Assistant: 35% → 85% (linear trajectory)
- Random: 30% (flat)
5. **Quen 2.5 7B**
- Direct: 35% → 45% (gradual rise)
- Beliefs: 40% → 50% (flat after interaction 2)
- Bayesian Assistant: 35% → 80% (steady climb)
- Random: 30% (flat)
6. **Quen 2.5 32B**
- Direct: 30% → 45% (consistent growth)
- Beliefs: 40% → 45% (minimal improvement)
- Bayesian Assistant: 35% → 80% (linear trajectory)
- Random: 30% (flat)
7. **GPT-4.1 Mini**
- Direct: 35% → 50% (moderate increase)
- Beliefs: 40% → 55% (steady climb)
- Bayesian Assistant: 35% → 85% (sharp rise)
- Random: 30% (flat)
8. **Gemini 1.5 Pro**
- Direct: 30% → 50% (consistent growth)
- Beliefs: 40% → 55% (moderate improvement)
- Bayesian Assistant: 35% → 85% (linear trajectory)
- Random: 30% (flat)
9. **Human**
- Direct: 35% → 45% → 40% → 50% → 45% (volatility)
- Beliefs: 40% → 45% → 50% → 48% → 52% (noise)
- Bayesian Assistant: 35% → 80% → 85% → 88% → 90% (steady climb)
- Random: 30% (flat)
- Error bars: ±5% variability in human performance
### Key Observations
1. **Bayesian Assistant Dominance**: All models show Bayesian Assistant outperforming others by 20-50% at 5 interactions, with linear growth patterns.
2. **Direct vs Beliefs**: Direct consistently outperforms Beliefs except in GPT-4.1 Mini (interaction 5: 50% vs 55%).
3. **Human Variability**: Human performance shows significant fluctuation (±5% error bars), unlike model stability.
4. **Diminishing Returns**: Most models plateau after 3-4 interactions, except Bayesian Assistant which maintains linear growth.
5. **Random Baseline**: All charts maintain 30% accuracy for Random, suggesting a performance floor.
### Interpretation
The data demonstrates that Bayesian Assistant integration significantly enhances model performance across all architectures, suggesting it provides critical contextual grounding. The consistent linear growth of Bayesian Assistant contrasts with plateauing trends in other methods, indicating its scalability with interaction count. Human performance volatility highlights the challenge of replicating model consistency in human-AI collaboration. The Direct method's superiority over Beliefs (except in GPT-4.1 Mini) suggests that belief-based reasoning may introduce unnecessary complexity without proportional accuracy gains. The Random baseline's flat 30% performance establishes a minimum threshold for meaningful interaction design.