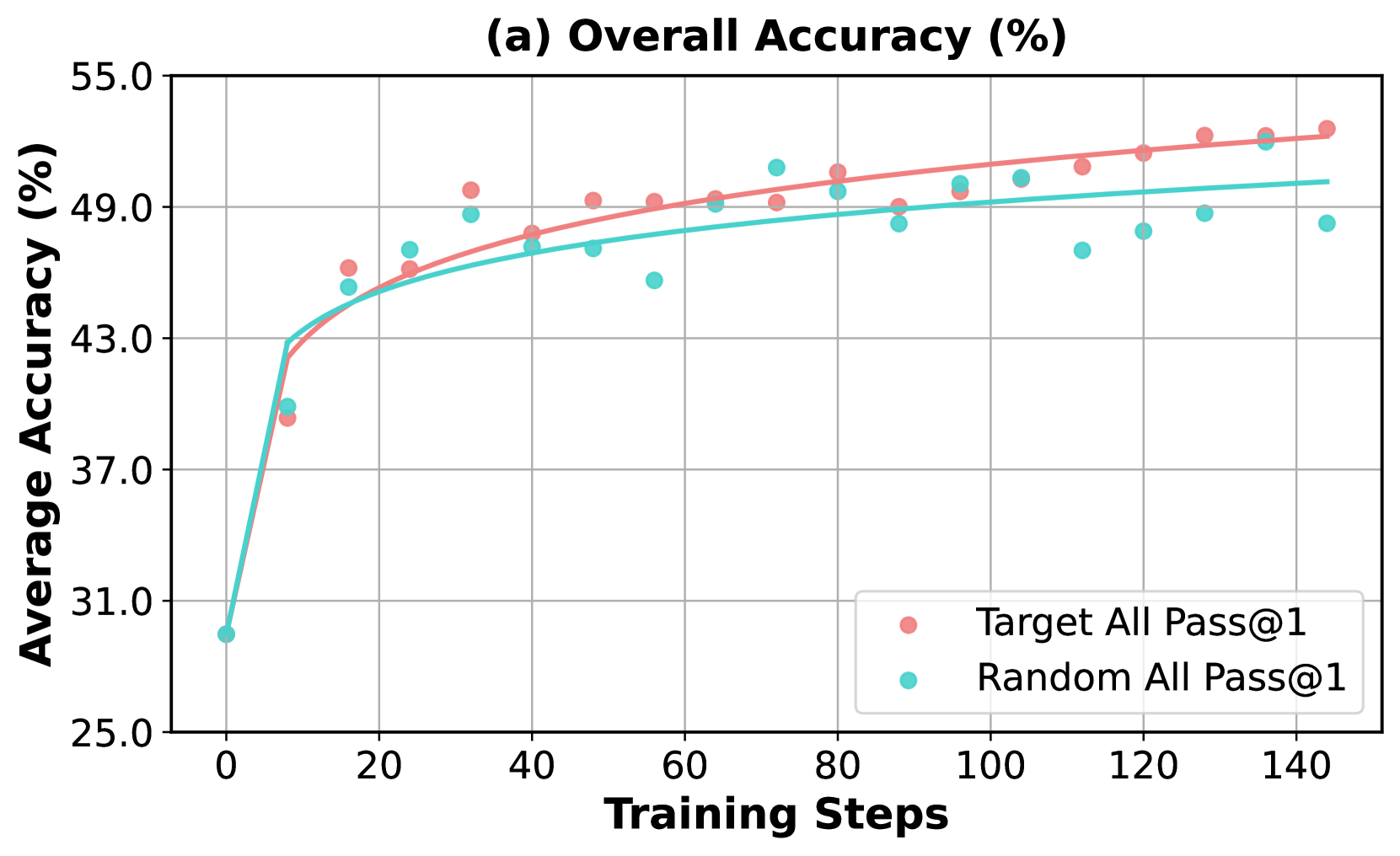
## Line Chart: Overall Accuracy (%)
### Overview
The chart visualizes the convergence of two training strategies ("Target All Pass@1" and "Random All Pass@1") over 140 training steps, showing their average accuracy percentages. Both lines exhibit rapid initial improvement followed by plateauing performance, with the Target strategy consistently outperforming the Random strategy.
### Components/Axes
- **X-axis**: Training Steps (0–140, increments of 20)
- **Y-axis**: Average Accuracy (%) (25–55%, increments of 2%)
- **Legend**:
- Red dots: Target All Pass@1
- Teal dots: Random All Pass@1
- **Placement**: Legend in bottom-right corner
### Detailed Analysis
1. **Target All Pass@1 (Red Line)**:
- Starts at ~30% accuracy at 0 steps.
- Sharp rise to ~43% by 20 steps.
- Gradual increase to ~49% by 140 steps, with minor fluctuations (e.g., ~48.5% at 100 steps).
- Final plateau near 50% accuracy.
2. **Random All Pass@1 (Teal Line)**:
- Begins at ~28% accuracy at 0 steps.
- Rapid ascent to ~43% by 20 steps.
- Slower convergence to ~49% by 140 steps, with notable variability (e.g., ~48.2% at 120 steps, ~48.8% at 140 steps).
- Slight downward trend after 100 steps.
### Key Observations
- **Performance Gap**: Target strategy maintains ~1–2% higher accuracy than Random across all steps.
- **Convergence**: Both lines plateau near 49% accuracy, suggesting diminishing returns after ~80 steps.
- **Volatility**: Random strategy shows larger fluctuations (e.g., ~47.5% at 60 steps vs. ~49.2% at 80 steps).
### Interpretation
The data demonstrates that the Target All Pass@1 strategy achieves superior and more stable performance compared to Random All Pass@1. The rapid early improvement for both methods indicates effective initial learning, while the plateau suggests saturation of model capacity or data complexity limits. The Random strategy's volatility may reflect sensitivity to initialization or data shuffling, whereas the Target strategy's consistency implies robust optimization. The ~1% accuracy gap highlights the importance of targeted training over random approaches in this context.