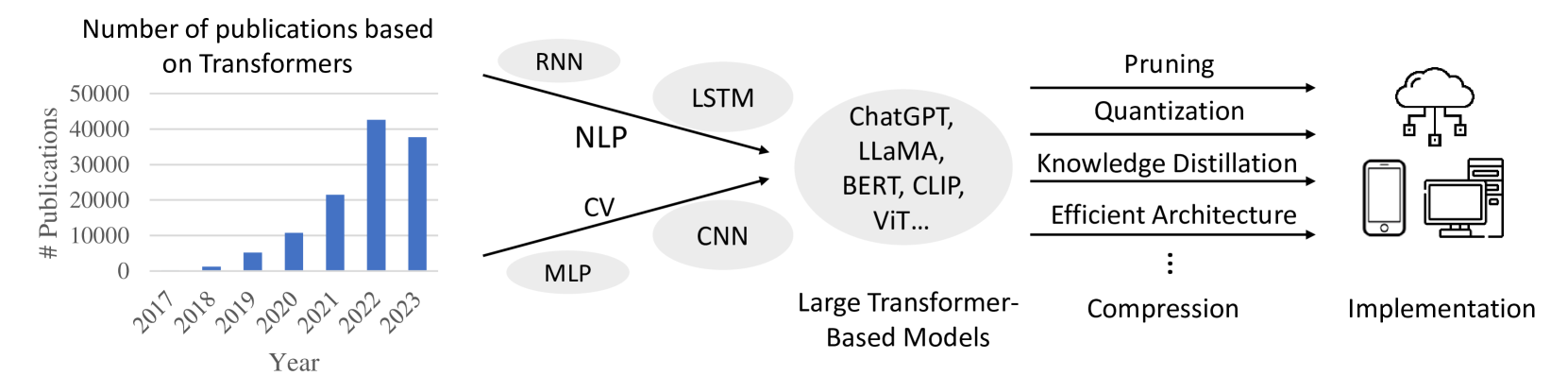
## Bar Chart: Number of Publications Based on Transformers (2017–2023)
### Overview
A vertical bar chart illustrates the exponential growth in publications related to Transformers from 2017 to 2023. The y-axis represents the number of publications (0–50,000), while the x-axis spans the years 2017–2023. A secondary diagram on the right contextualizes the evolution of Transformer-based models and their implementation techniques.
### Components/Axes
- **Bar Chart**:
- **X-axis (Year)**: Labeled "Year" with ticks for 2017–2023.
- **Y-axis (# Publications)**: Labeled "# Publications" with increments of 10,000 up to 50,000.
- **Bars**: Blue-colored bars represent annual publication counts.
- **Diagram**:
- **Left Side**: Traditional machine learning (ML) models (RNN, LSTM, NLP, CV, CNN, MLP) grouped under "Large Transformer-Based Models."
- **Center**: Arrows connect traditional models to large Transformer-based models (ChatGPT, LLaMA, BERT, CLIP, ViT...).
- **Right Side**: Implementation techniques (Pruning, Quantization, Knowledge Distillation, Efficient Architecture, Compression) linked to deployment icons (cloud, devices).
### Detailed Analysis
- **Bar Chart Trends**:
- **2017**: 0 publications (no data).
- **2018**: ~1,000 publications (smallest bar).
- **2019**: ~5,000 publications.
- **2020**: ~10,000 publications.
- **2021**: ~20,000 publications.
- **2022**: ~40,000 publications (peak).
- **2023**: ~35,000 publications (slight decline from 2022).
- **Trend Verification**: Bars show a consistent upward trajectory until 2022, followed by a minor drop in 2023.
- **Diagram Flow**:
- Traditional models (RNN, LSTM, etc.) feed into NLP/CV domains.
- Large Transformer-based models (ChatGPT, BERT, etc.) dominate the center, indicating their centrality in modern AI.
- Implementation techniques (pruning, quantization, etc.) are positioned as downstream optimizations for deployment.
### Key Observations
1. **Exponential Growth**: Publications surged from ~1,000 (2018) to ~40,000 (2022), reflecting rapid adoption of Transformers.
2. **2023 Dip**: A ~12.5% decline from 2022 to 2023 suggests potential market saturation or shifting research focus.
3. **Model Evolution**: The diagram highlights the transition from classical ML to Transformer-based architectures, emphasizing their dominance in NLP/CV.
4. **Implementation Focus**: Techniques like pruning and quantization address computational challenges, critical for real-world deployment.
### Interpretation
- **Research Trajectory**: The bar chart underscores the explosive growth of Transformer research, likely driven by breakthroughs in NLP (e.g., BERT, GPT). The 2023 dip may reflect consolidation or a pivot toward practical applications.
- **Technical Ecosystem**: The diagram maps the lifecycle of Transformer models, from foundational algorithms (RNN/LSTM) to advanced implementations (pruning, compression). This suggests a maturation phase where efficiency and scalability are prioritized.
- **Anomalies**: The 2023 decline warrants investigation—could it signal a shift toward specialized models (e.g., vision transformers) or ethical/regulatory constraints?
- **Implications**: The emphasis on implementation techniques highlights the industry’s focus on deploying large models in resource-constrained environments (e.g., edge devices).
## Diagram: Evolution of Transformer-Based Models and Implementation Techniques
### Overview
A flowchart-style diagram traces the progression from traditional ML models to large Transformer-based architectures and their optimization strategies for deployment.
### Components/Axes
- **Left Side**: Traditional ML models (RNN, LSTM, NLP, CV, CNN, MLP) grouped under "Large Transformer-Based Models."
- **Center**: Arrows connect traditional models to Transformer variants (ChatGPT, LLaMA, BERT, CLIP, ViT...).
- **Right Side**: Implementation techniques (Pruning, Quantization, Knowledge Distillation, Efficient Architecture, Compression) linked to deployment icons (cloud, devices).
### Content Details
- **Traditional Models**: RNN, LSTM, CNN, and MLP represent pre-Transformer paradigms.
- **Transformer Variants**:
- **NLP**: ChatGPT, LLaMA, BERT.
- **CV**: CLIP, ViT.
- **Implementation Techniques**:
- **Pruning/Quantization**: Reduce model size for efficiency.
- **Knowledge Distillation**: Transfer knowledge from large to smaller models.
- **Efficient Architecture**: Optimize computational graphs.
- **Compression/Implementation**: Deploy models on cloud/edge devices.
### Key Observations
1. **Model Specialization**: Transformers dominate NLP (ChatGPT, BERT) and CV (CLIP, ViT), reflecting their versatility.
2. **Optimization Pipeline**: Techniques like pruning and quantization address the computational demands of large models.
3. **Deployment Focus**: Icons (cloud, devices) emphasize real-world applicability, bridging research and practice.
### Interpretation
- **Technical Maturity**: The diagram illustrates a shift from theoretical exploration (2017–2022) to practical deployment (2023+), aligning with the bar chart’s publication trends.
- **Interdisciplinary Impact**: Transformers bridge NLP and CV, enabling cross-domain applications (e.g., multimodal models like CLIP).
- **Future Directions**: The emphasis on compression and efficient architecture suggests ongoing efforts to democratize access to large models via lightweight variants.
## Final Notes
- **Data Limitations**: Exact publication counts are approximate due to the absence of a numerical legend.
- **Contextual Gaps**: The 2023 dip lacks explanatory context—further analysis of publication topics (e.g., ethics, hardware constraints) could clarify this anomaly.
- **Strategic Insight**: The ecosystem depicted in the diagram highlights the need for interdisciplinary collaboration to advance Transformer-based AI responsibly.